
Recognition of unsafe behaviors of key position personnel in coal mines based on improved YOLOv7 and ByteTrack
-
摘要: 应用人工智能技术对矿井提升机司机等煤矿关键岗位人员的行为进行实时识别,防止发生设备误操作等危险情况,对保障煤矿安全生产具有重要意义。针对基于图像特征的人员行为识别方法存在的抗背景干扰能力差与实时性不足问题,提出了一种基于改进YOLOv7和ByteTrack的煤矿关键岗位人员不安全行为识别方法。首先,基于MobileOne和C3对YOLOv7目标检测模型骨干与头部网络进行轻量化改进,提高模型推理速度;其次,融合ByteTrack跟踪算法,实现工作人员跟踪锁定,提高抗背景干扰能力;然后,采用MobileNetV2优化OpenPose的网络结构,提高对骨架特征的提取效率;最后,通过时空图卷积网络(ST−GCN)分析人体骨架关键点在时间序列上的空间结构和动态变化,实现对不安全行为的分析识别。实验结果表明:MobileOneC3−YOLO模型的精确率达93.7%,推理速度较YOLOv7模型提高了52%;融合ByteTrack的人员锁定模型锁定成功率达97.1%;改进OpenPose模型内存需求减少了170.3 MiB,在CPU与GPU上的推理速度分别提升了74.7%和54.9%;不安全行为识别模型对疲劳睡岗、离岗、侧身交谈和玩手机4种不安全行为的识别精确率达93.5%,推理速度达18.6 帧/s。Abstract: The application of artificial intelligence technology can real-time recognize the behavior of key position personnel in coal mines, such as mine hoist drivers, to prevent dangerous situations such as equipment misoperation. It is of great significance for ensuring coal mine safety production. The personnel behavior recognition method based on image features has problems of poor resistance to background interference and insufficient real-time performance. In order to solve the above problems, a coal mine key position personnel unsafe behavior recognition method based on improved YOLOv7 and ByteTrack is proposed. Firstly, based on MobileOne and C3, lightweight improvements are made to the backbone and head network of the YOLOv7 object detection model to improve the inference speed of the model. Secondly, integrating ByteTrack tracking algorithm, to achieve the tracking and locking of personnel is achieved, and the capability to resist background interference is improved. Thirdly, MobileNetV2 is used to optimize the network structure of OpenPose and improve the efficiency of skeleton feature extraction. Finally, the spatial temporal graph convolutional networks (ST−GCN) is used to analyze the spatial structure and dynamic changes of the key points of the human skeleton in the time series, achieving the analysis and recognition of unsafe behaviors. The experimental results show that the precision of the MobileOneC3−YOLO model reaches 93.7%, and the inference speed is improved by 52% compared to the YOLOv7 model. The success rate of personnel locking model integrating ByteTrack reaches 97.1%. The improved OpenPose model reduces memory requirements by 170.3 MiB. The inference speed on CPU and GPU is improved by 74.7% and 54.9%, respectively; The recognition precision of the unsafe behavior recognition model for four types of unsafe behaviors, including fatigue sleeping on duty, leaving work, side talking, and playing with mobile phones, reaches 93.5%, and the inference speed reaches 18.6 frames per second.
-
0. 引言
煤矿生产各个岗位的工作人员必须保持精神高度集中,才能确保安全生产。然而,由于安全监管不到位、员工安全意识参差不齐,人员不安全行为仍然是导致安全事故的主要原因[1-2]。因此,对煤矿生产中矿井提升机和绞车司机、变电站值班人员、井口信号把钩工(简称信把工)等关键岗位工作人员的行为进行识别,及时、准确地警示不安全行为,防止由于不安全行为造成设备误操作等安全隐患,对保障煤矿安全生产具有重要意义。
随着智慧矿山建设的推进和煤矿生产安全需求的不断提高[3],人工智能技术在煤矿人员行为识别中逐步得到应用[4]。刘浩等[5]采用MobileNetV3与时空图卷积网络(Spatial Temporal Graph Convolutional Networks,ST−GCN)实现对井下员工静态与动态不安全行为的识别。温廷新等[6]提出了基于迁移学习和深度残差网络的图像识别方法,对煤矿工人的不安全行为进行分类和识别,但该方法对复杂动作的识别率较低。李占利等[7]提出了一种基于3D−Attention的矿工行为识别算法,实现了对煤矿井下跑、跳等不安全行为的识别。王宇等[8]通过SlowOnly网络提取RGB模态,并与从骨骼模态中提取的特征进行融合,实现对井下人员不安全行为的识别。基于图像特征的行为识别方法在煤矿场景虽然得到了一定应用,但仍面临以下挑战:① 煤矿场景复杂多变,监控图像背景中无关人员的活动会对不安全行为识别造成干扰。② 常见算法实时性低,无法及时对不安全行为进行预警和干预。
针对上述问题,本文综合考虑矿井人员的姿态与时序特征,提出一种基于改进YOLOv7和ByteTrack的煤矿关键岗位人员不安全行为识别方法。通过MobileOne与C3模块对YOLOv7进行轻量化改进,构建基于MobileOneC3−YOLO的关键岗位人员实时检测模型,获取人员准确位置。通过ByteTrack跟踪算法精确锁定目标人员,排除背景中无关人员对不安全行为识别的干扰,提升不安全行为识别准确率和效率。最后,结合改进OpenPose模型和ST−GCN实现煤矿关键岗位人员不安全行为的分析识别。
1. 煤矿关键岗位人员不安全行为识别框架
通过现场调研统计,矿井提升机和绞车司机、变电站值班人员、井口信把工等关键岗位人员不安全行为主要包括疲劳睡岗、离岗、玩手机、侧身交谈,这些行为严重分散了工作人员的注意力,易引发误操作等安全事故。因此,本文主要针对以上4种不安全行为进行识别分析。
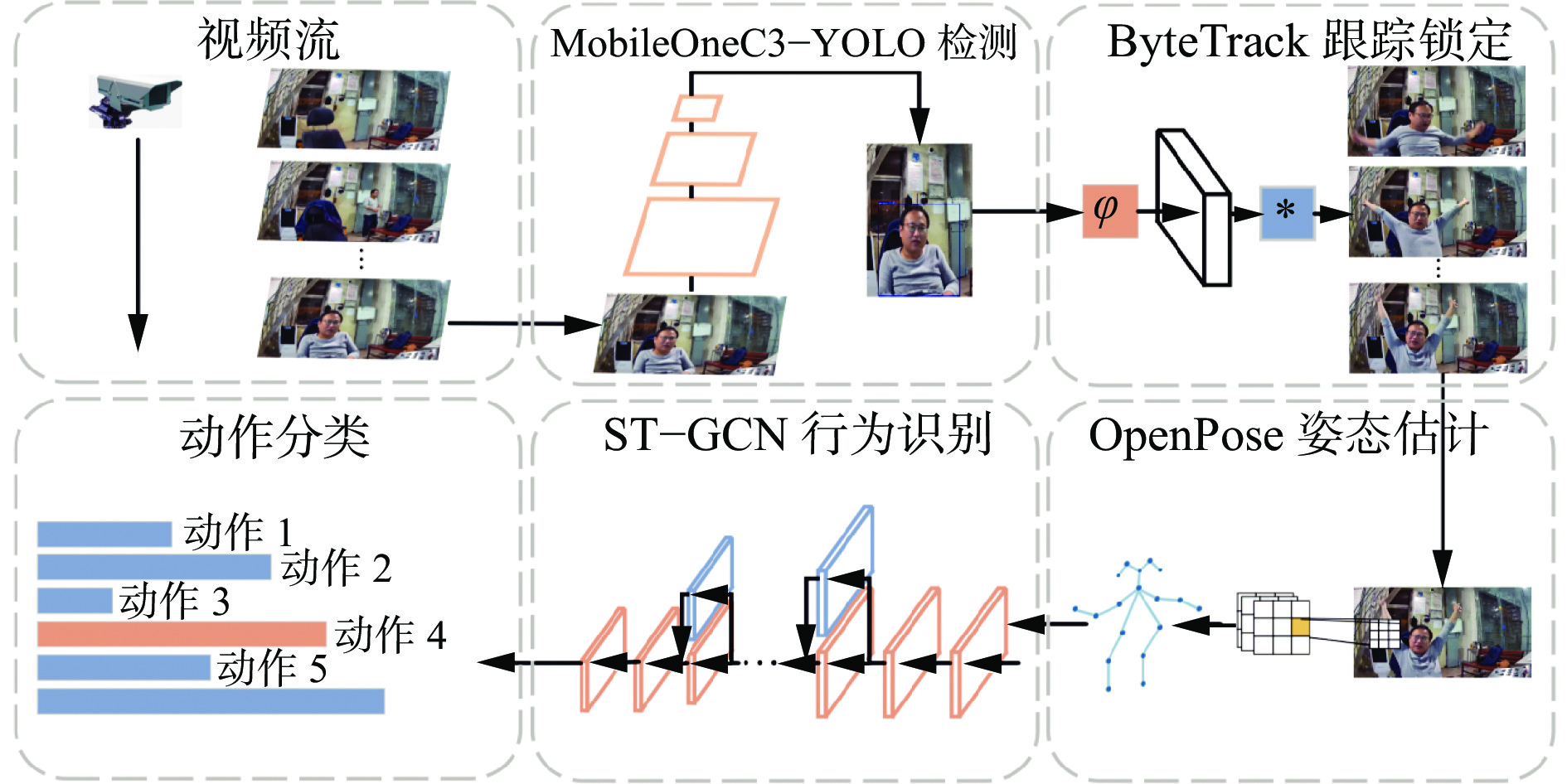
煤矿关键岗位人员不安全行为识别框架如图1所示,其中$\varphi $为特征提取器,$ * $为特征比较器。首先,通过摄像机获取煤矿关键人员监控视频,基于MobileOneC3−YOLO模型获取人员准确位置,为关键岗位人员跟踪提供稳定、准确的位置信息。其次,为排除背景中无关人员对不安全行为识别造成的干扰,采用ByteTrack实现关键岗位人员追踪锁定,提升不安全行为识别的鲁棒性。然后,将已锁定人员检测框送入改进OpenPose模型,提取关键岗位人员的骨架特征,实现人体姿态估计。最后,基于ST−GCN对人员姿态的时序特征进行分析,实现煤矿关键岗位人员不安全行为识别。
2. 煤矿关键岗位不安全行为识别方法
2.1 基于MobileOneC3−YOLO的关键岗位人员实时检测模型
快速、精准地对关键岗位人员进行定位是实现不安全行为识别的第1步。YOLOv7作为经典的目标检测框架,检测精度较YOLOv5提升明显,同时较YOLOv8降低了模型体积[9]。考虑到实时性与检测精度的双重需求,以及YOLOv7设计灵活的特点,采用YOLOv7作为目标检测模型。然而,YOLOv7复杂的网络结构使其在并行处理大量视频时存在严重的计算延迟。对此,本文采用MobileOne与C3模块对YOLOv7进行轻量化改进,构建MobileOneC3−YOLO人员检测模型,在维持人员检测精度的同时,提升检测实时性。
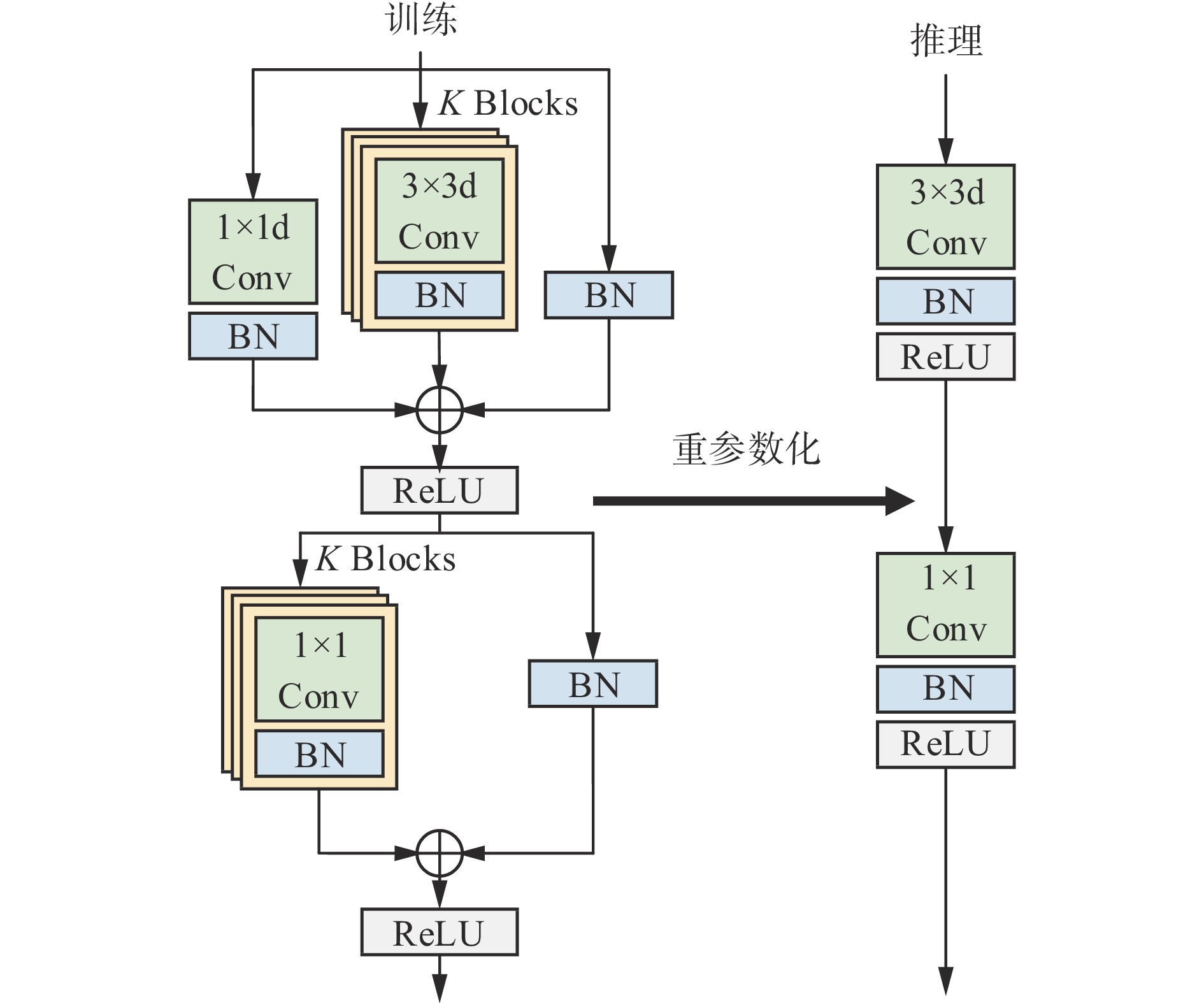
MobileOne是基于卷积神经网络架构的轻量级骨干网络,利用结构重参数化解耦训练阶段和推理阶段[10],其结构如图2所示。训练阶段主要包括深度卷积和点卷积2个部分,通过超参数K控制重参数化的分支数。深度卷积部分由2个卷积模块和单独的批标准化(Batch Normalization,BN)层构成残差结构,点卷积部分则由1个卷积模块和单独的BN层构成残差结构。推理阶段,通过重参数化将深度卷积和点卷积分别转换为仅包含1个卷积和1个激活函数的等效结构,从而显著提升模块的推理速度,同时保证推理精度。
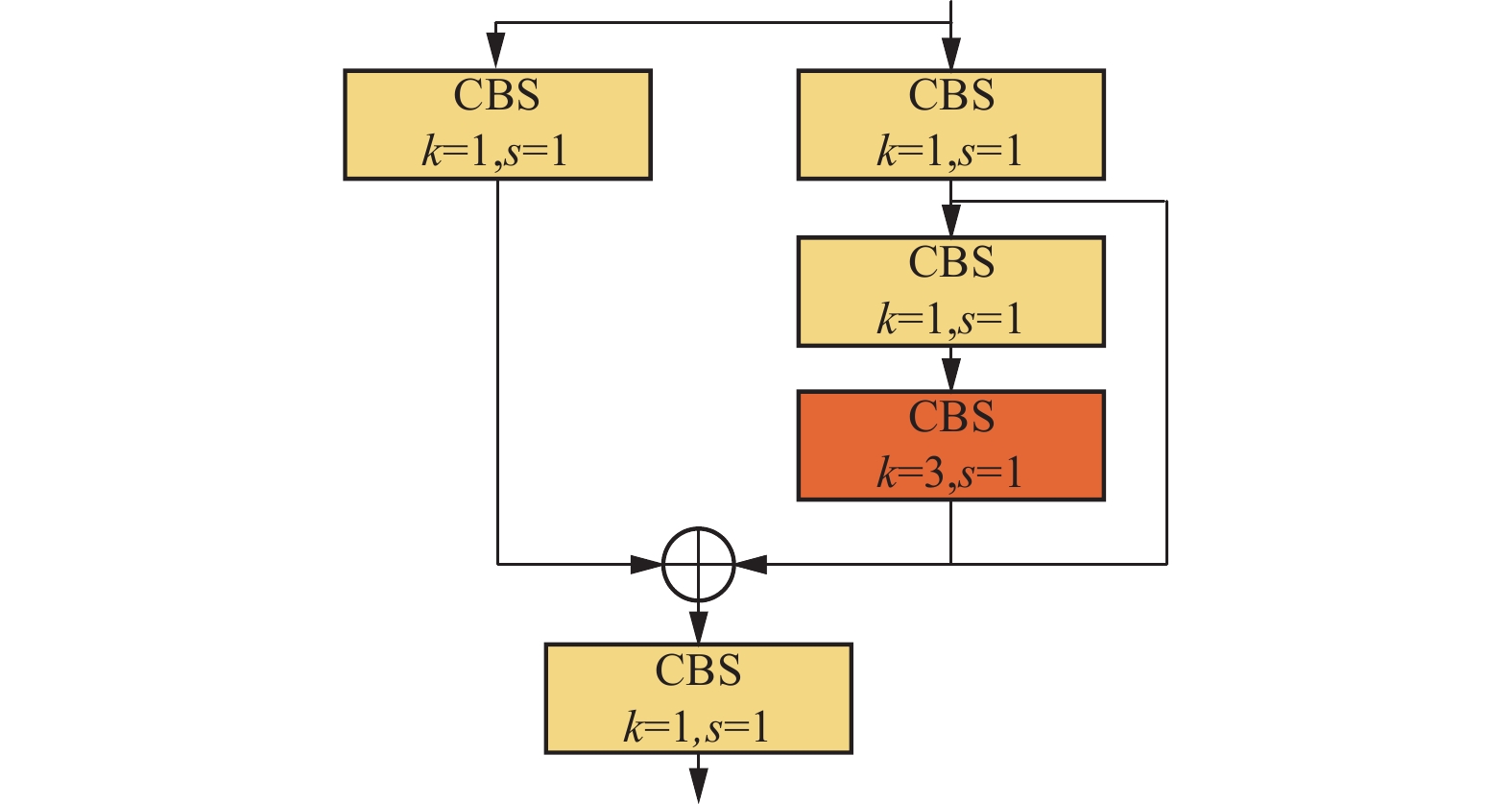
C3模块在跨阶段局部网络(Cross Stage Partial Network,CSPNet)基础上融入残差连接,旨在提升网络学习能力和效率,同时减小模型尺寸[11]。C3模块结构如图3所示。第1个分支包含3个CBS(卷积−批量归一化−SiLU激活函数)模块,用于深入提取和细化特征表示;第2个分支由1个CBS模块构成,目的是在不牺牲性能的前提下保持模块的高效性。2个分支最终合并,以增强特征表达。
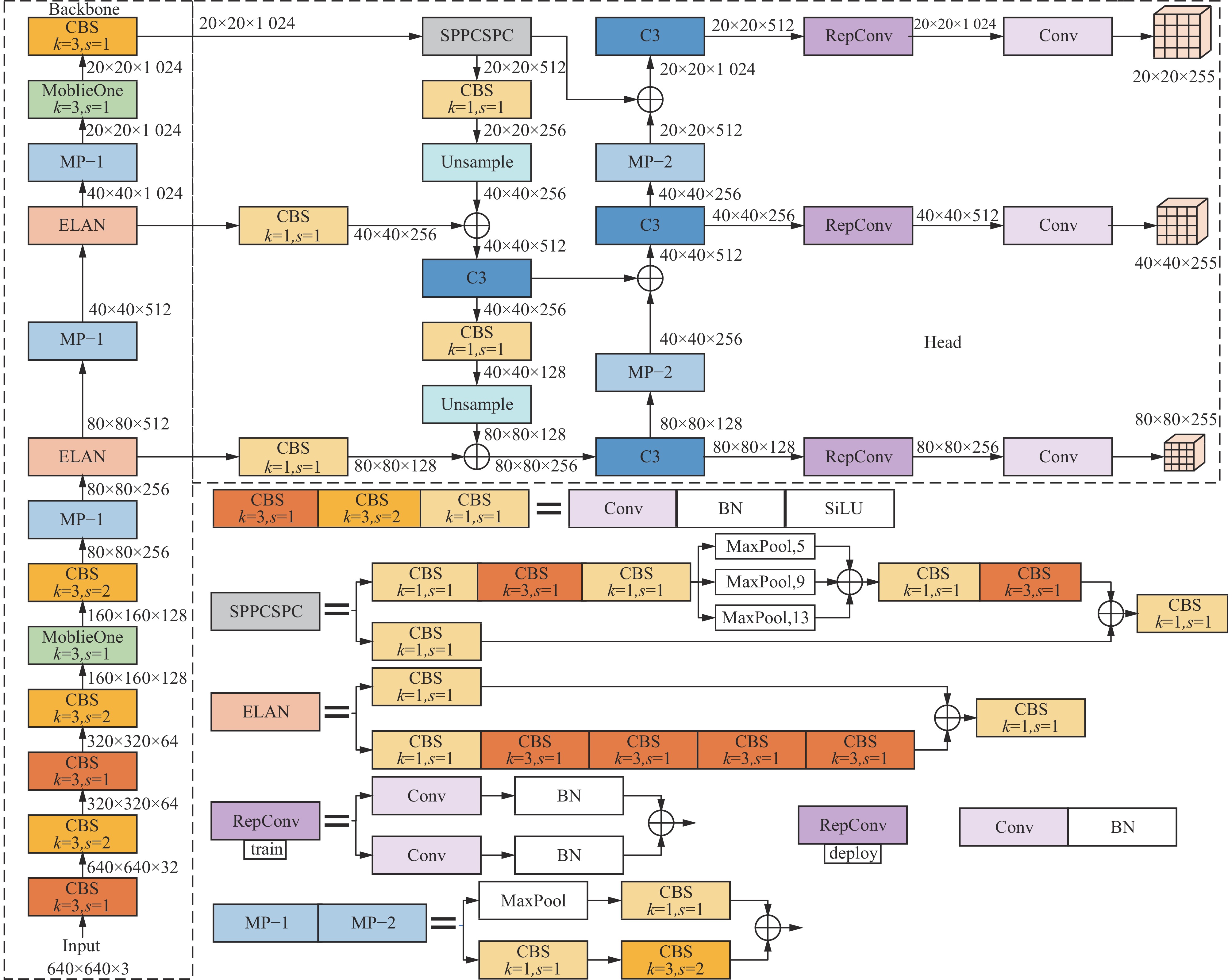
MobileOneC3−YOLO人员检测模型如图4所示。在保持YOLOv7模型优势的基础上,本文采用MobileOne改进YOLOv7的主干网络,并采用ReLU作为MobileOne的激活函数,以提高网络的计算效率和表达能力。此外,在模型的头部引入C3模块,以简化模型结构,进一步提升特征表达能力。
2.2 基于ByteTrack的关键岗位人员锁定方法
煤矿关键岗位人员不安全行为识别过程中,由于无关人员流动,在监控画面中产生了大量无关人员闯入、停留、走动等情况,给不安全行为识别带来了干扰,易导致误检和检测准确性降低。因此,时刻锁定关键岗位工作人员,排除无关人员对不安全行为识别产生的干扰,是提高检测鲁棒性的关键。本文利用ByteTrack跟踪算法[12]对视频中的人员进行跟踪,通过工作区域持续时间阈值法实现对关键岗位人员的锁定,排除背景中无关人员对不安全行为识别的干扰。
2.2.1 工作人员跟踪
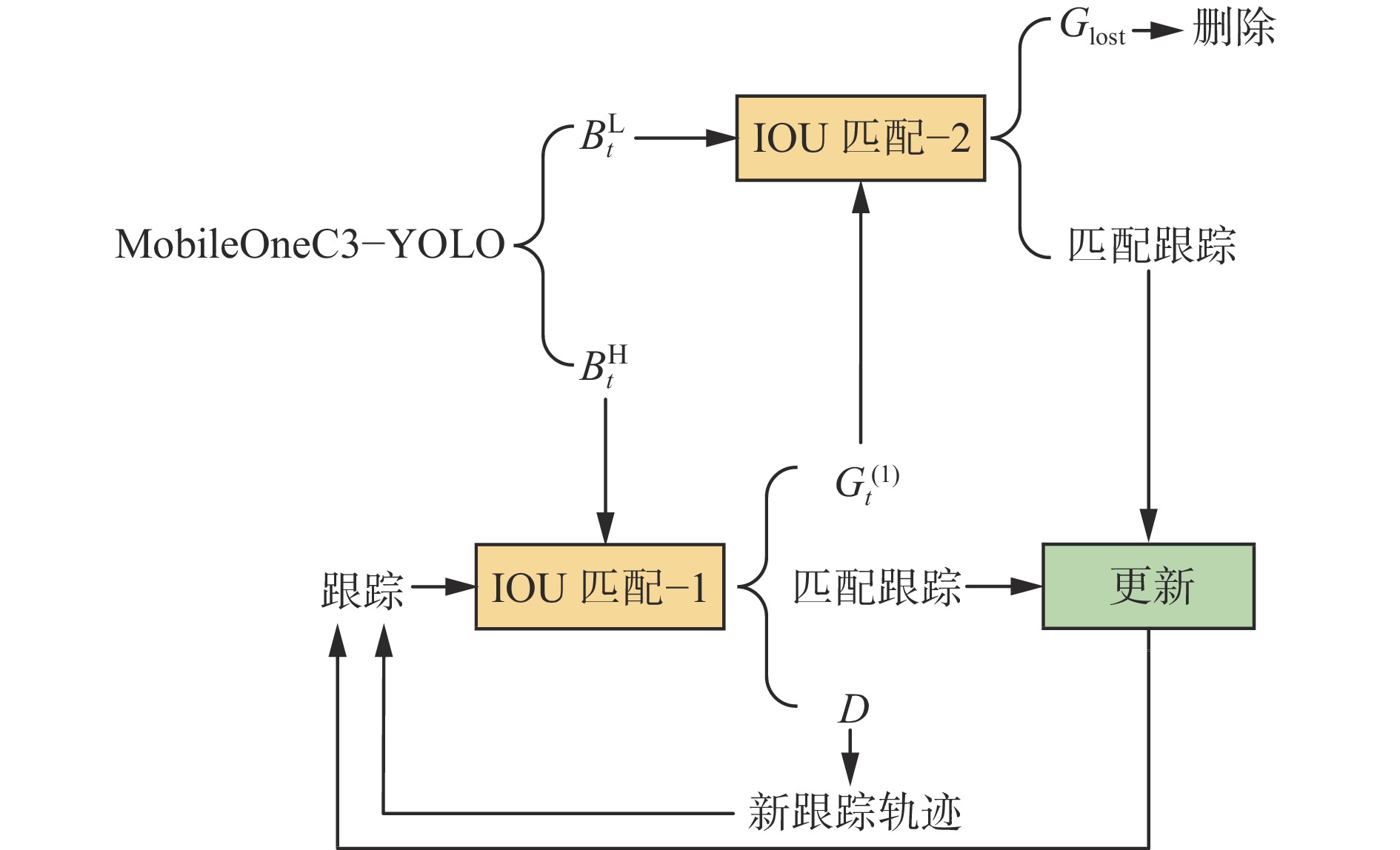
基于ByteTrack的跟踪流程如图5所示。首先,通过MobileOneC3−YOLO模型对视频的每一帧进行检测,得到检测框集合$ {B_t} $(t为时间)。对于每个检测框${b_{t}} \in {B_t}$,根据检测得分${S_{{{t}}}}$和设定的阈值$\theta $分类为高分$B_{{t}}^{\mathrm{H}}$和低分$B_{{t}}^{\mathrm{L}}$检测框。
高低分检测框分类规则为
$$ B_t^{\mathrm{H}} = \left\{ {{b_{t}} \in {B_t},{S_{t}} \geqslant \theta } \right\} $$ (1) $$ B_t^{\mathrm{L}} = \left\{ {{b_{t}} \in {B_t},{S_{t}} < \theta } \right\} $$ (2) 针对由连续检测框组成的轨迹集合${G_{t - 1}}$,通过卡尔曼滤波进行下一帧轨迹的预测,得到预测轨迹$ {\hat G_t} $,并与$B_{{t}}^{\mathrm{H}}$和$B_{{t}}^{\mathrm{L}}$检测框进行2次关联。
第1次关联:将$B_t^{\mathrm{H}}$与$ {\hat G_t} $进行关联,计算交并比匹配特征,并使用匈牙利算法进行匹配。对于匹配成功的轨迹,更新状态并加入当前帧轨迹集合${G_t}$,未能匹配跟踪轨迹的高分检测框放入集合$D$中,并新建跟踪轨迹,未匹配的轨迹放入$ G_t^{\left( 1 \right)} $。
第2次关联:将$B_t^{\mathrm{L}}$与$ G_{{t}}^{\left( 1 \right)} $进行关联,计算交并比匹配特征,并使用匈牙利算法进行匹配。更新匹配的轨迹并继续进行跟踪,对于超过特定帧数未匹配的轨迹${G_{{\mathrm{lost}}}}$进行删除。最终得到更新后的轨迹集合。每个轨迹集合对应了一个跟踪ID,代表一个跟踪目标,通过上述过程,完成对视频中所有人员的跟踪。
2.2.2 工作人员锁定
为实现对关键岗位工作人员的精确锁定,定义工作区域W和时间阈值T,对视频帧中每个跟踪目标d,判断其是否位于定义的工作区域内。对位于工作区域内的目标,系统累计其在工作区域内的停留时间,并进一步评估该时间是否达到或超过时间阈值。若目标的累计停留时间达到或超过时间阈值,则系统将其识别为工作人员进行持续锁定,并通过后续步骤进行姿态估计。人员锁定过程伪代码如下。
算法1:人员锁定过程
1 Procedure TrackWorkers(Video,W,T)
2 Workers ← empty set; // 初始化工作人员集合
3 Tracked ← empty map; // 初始化每个目标的累计停留时间映射
4 for each frame F in Video do
5 Detected ← DetectTargetsInFrame(F); // 检测当前帧中所有目标
6 for d in Detected do //遍历当前帧检测到的每个目标
7 if IsInWorkArea(d, W) then
8 Tracked[d] = Tracked.get(d, 0) + Δt; //累计目标的停留时间
9 else
10 Tracked[d] = 0;
11 if Tracked[d] ≥ T and d not in Workers then //如果目标的累计停留时间达到阈值且尚未被识别为工作人员
12 Workers.add(d); //将目标加入工作人员集合
13 end for;
14 end for;
15 UpdateTracking(Tracked, Workers); //更新跟踪信息,以便持续跟踪已锁定的工作人员
16 end Procedure;
2.3 基于改进OpenPose的人体关键点提取
对跟踪锁定的人员检测框中的目标,采用OpenPose进行骨架特征提取[13]。OpenPose使用VGG−19[14]网络作为特征提取网络,但VGG−19缺乏残差连接,限制了其处理深层特征时的效率和速度,不利于快速响应煤矿生产现场的紧急事件。鉴此,本文采用MobileNetV2替代VGG−19作为OpenPose的特征提取网络,这一改进可在保证模型准确性的同时减少参数量,从而有效提升推理速度和效率。
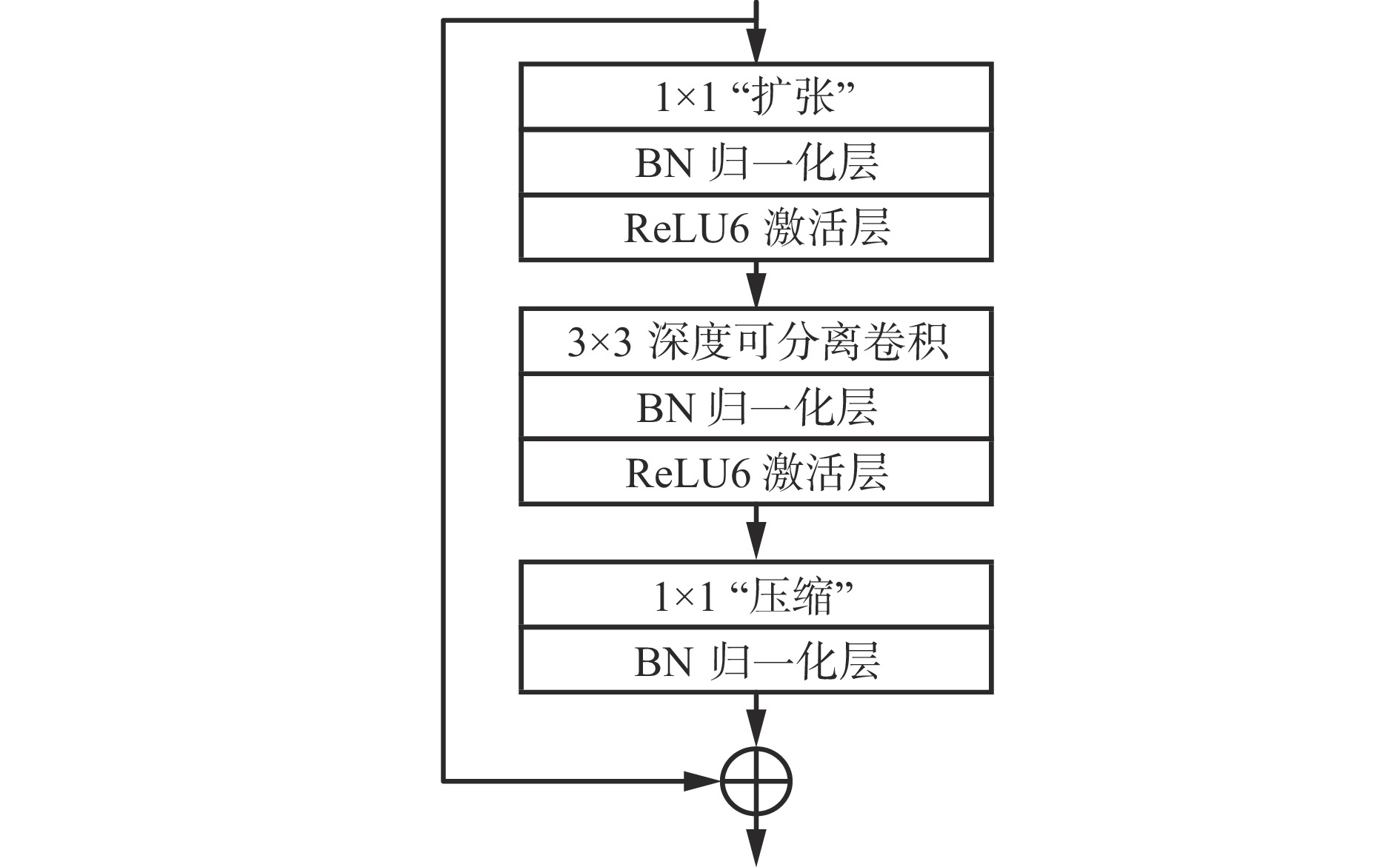
MobileNetV2主要由扩张、深度可分离卷积、压缩3个部分组成,通过引入倒残差结构来提高模型的性能和效率[15]。MobileNetV2倒残差结构如图6所示。
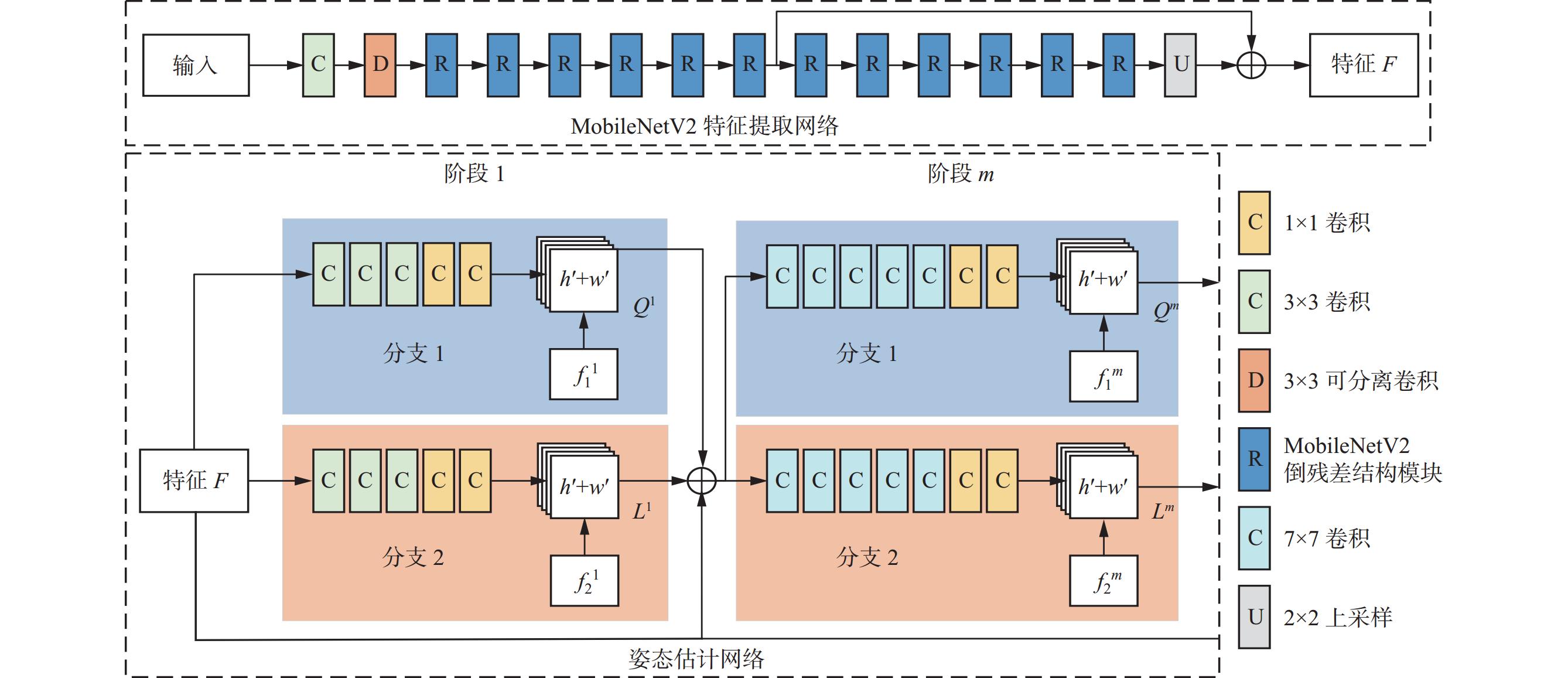
改进OpenPose网络结构如图7所示。$h',\;w' $分别为特征图的高和宽;$ f_1^m,\; f_2^m $分别分支1和分支2在阶段m的损失函数。通过MobileNetV2对视频帧进行特征提取,将提取的特征输入姿态估计网络。姿态估计网络包含6个阶段,每个阶段包含2个分支:分支1用于预测关键点部位置信图Qm,分支2 用于预测部位亲和场Lm。考虑到关键点两两相连的情况,执行二分匹配,以关联身体部位候选关键点,利用匈牙利算法在图像中找到身体部位与人体的最优匹配,最终解析出目标的骨架姿态。
2.4 基于ST−GCN的行为识别
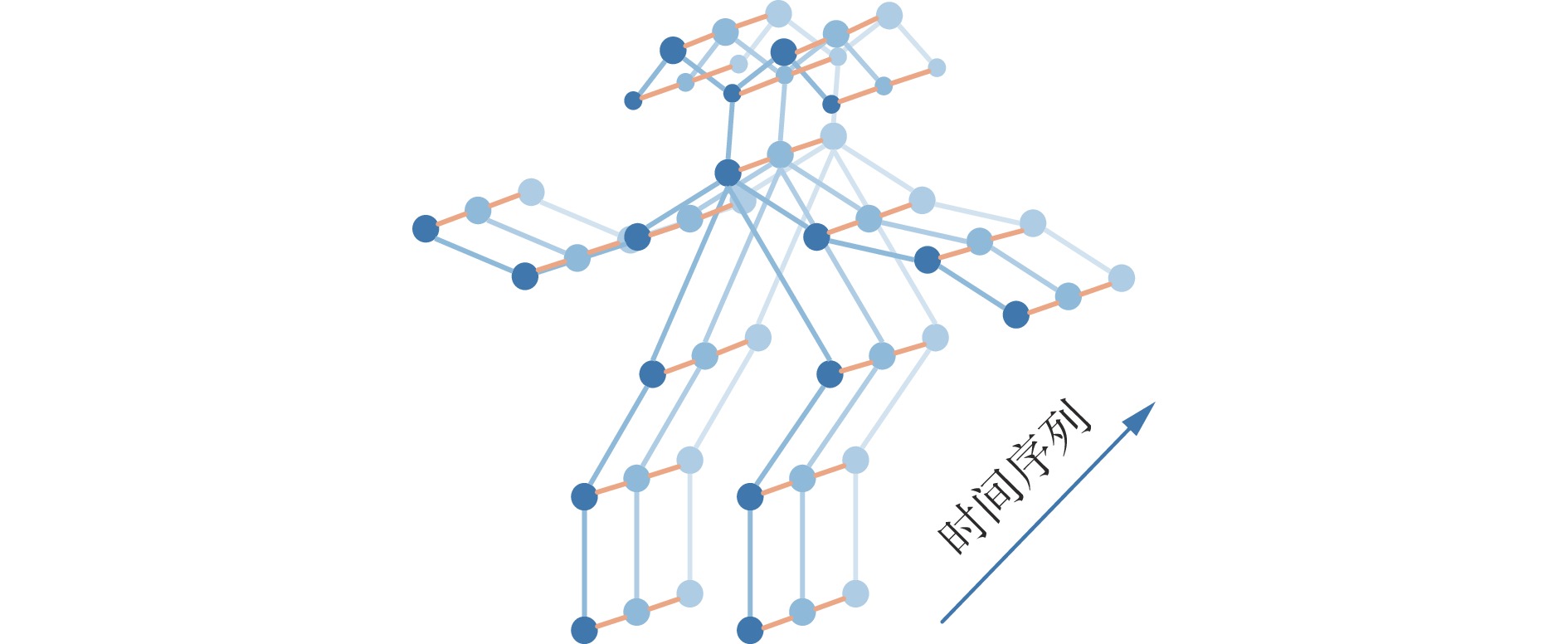
结合改进OpenPose提取的骨架序列,采用ST−GCN对动态不安全行为进行识别。ST−GCN是图卷积网络的扩展[16],通过引入时间卷积网络[17],设计了用于动作识别的人体骨架时空图,以捕捉人体骨骼关节空间配置的模式及骨架序列中的时间动态。将提取的骨架信息按帧排列,相邻帧之间相同关节点相连,得到一个以图数据形式呈现的骨架时空图,如图8所示。其中圆点为人体的18个关节点,蓝色线条表示单帧中人体内关节点的连接,橙色线条表示相邻帧之间同一关节点的连接。
骨架时空图可表示为
$$ \psi = \left( {V,\varPhi } \right) $$ (3) $$ V = \left\{ {{v_{xi}}\left| {x = 1, 2,\cdot \cdot \cdot ,X;i = 1,2, \cdot \cdot \cdot ,18} \right.} \right\} $$ (4) $$ \varPhi = \left( {{\varPhi _1},{\varPhi _2}} \right) $$ (5) 式中:V为关节点集合;Φ为骨架序列的连接边集合;vxi为骨架序列第x帧中的第i个关节点;X为总帧数;Φ1为空间域边子集,表示单帧骨架内所有关节点的空间连接信息,${\varPhi _1} = \left\{ {{v_{xi}}{v_{xj}}} \right\}$(j=1,2,···,18);Φ2为时间域边子集,表示第$x$个和第$x + 1$个连续帧之间相同关节点的时间连接信息,${\varPhi _2} = \left\{ {{v_{xi}}{v_{\left( {x + 1} \right)i}}} \right\}$。
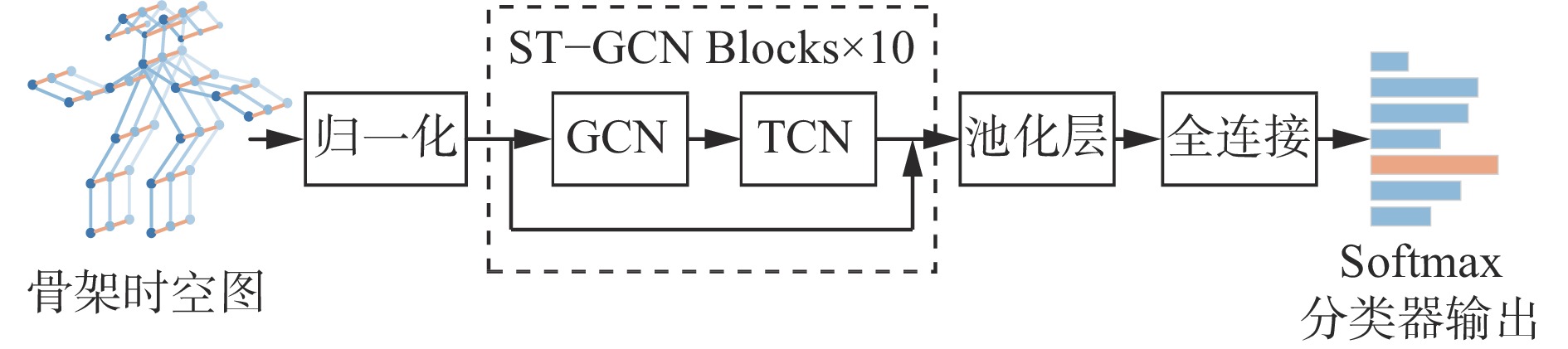
通过批量归一化层对骨架时空图数据进行归一化处理后,经过10个时空图卷积层进行卷积;再经过池化层进行平均池化,得到固定大小的特征向量;最后通过全连接层,由Softmax分类器输出识别结果。ST−GCN识别流程如图9所示。
3. 实验结果与分析
3.1 数据集构建与实验环境配置
本文视频数据来自淮南某煤矿绞车司机室、上下井口打点硐室等关键岗位,通过Python抽帧获得5 241张图像,初步构建煤矿关键岗位人员检测数据集。为提高模型泛化能力,采用添加噪声、裁剪、改变亮度、旋转、镜像等方式进行数据增强,增强后的数据集包含36 687张图像,以8∶2的比例划分为训练集(29 350张)和验证集(7 337张),标签类别为“Person”。此外,针对疲劳睡岗、离岗、侧身交谈和玩手机4种不安全行为,提取3 558个时长为6~8 s、帧率为25帧/s的煤矿关键岗位人员不安全行为数据样本。基于改进OpenPose提取人体骨架姿态信息,构建煤矿关键岗位人员不安全行为数据集,同样以8∶2的比例划分训练集和验证集。煤矿关键岗位人员检测数据集如图10所示。
实验使用的深度学习框架均为PyTorch 1.8.1版本,Python版本为3.8.5,服务器配置为Intel Core i9−12900 K CPU,NVIDIA GeForce RTX3090 GPU,64 GiB RAM。
3.2 评价指标
为了有效评估模型性能,采用常见评价指标对模型进行评估,具体指标见表1。其中(↑)表示数值越高效果越好,(↓)表示数值越高效果越差;TP为被正确检测出的人员数,FP为误检测人员总数,FN为漏检测人员总数,GT为真实的人员标签,IDSW为ID切换次数。
表 1 评价指标Table 1. Evaluation indexes评价指标 定义 计算公式 Precision(↑) 精确率 $ \dfrac{{{\mathrm{TP}}}}{{{\mathrm{TP}} + {\mathrm{FP}}}}$ Params(↓) 参数量 — AP(↑) 关键点相似度为[0.50,0.55,···,0.95]时
10个位置的平均精确率— 帧率(↑) 每秒处理的帧数 $ \dfrac{{总帧数}}{{时间}} $ MOTA(↑) 多目标跟踪准确率 $ 1 - \dfrac{{{\mathrm{FN}} + {\mathrm{FP}} + {\mathrm{IDSW}}}}{{{\mathrm{GT}}}}$ IDF1(↑) ID调和均值 $ \dfrac{{2{\mathrm{TP}}}}{{2{\mathrm{TP}} + {\mathrm{FP }}+ {\mathrm{FN}}}}$ FP(↓) 误跟踪目标数 — FN(↓) 漏跟踪目标数 — 3.3 人员检测模型性能分析
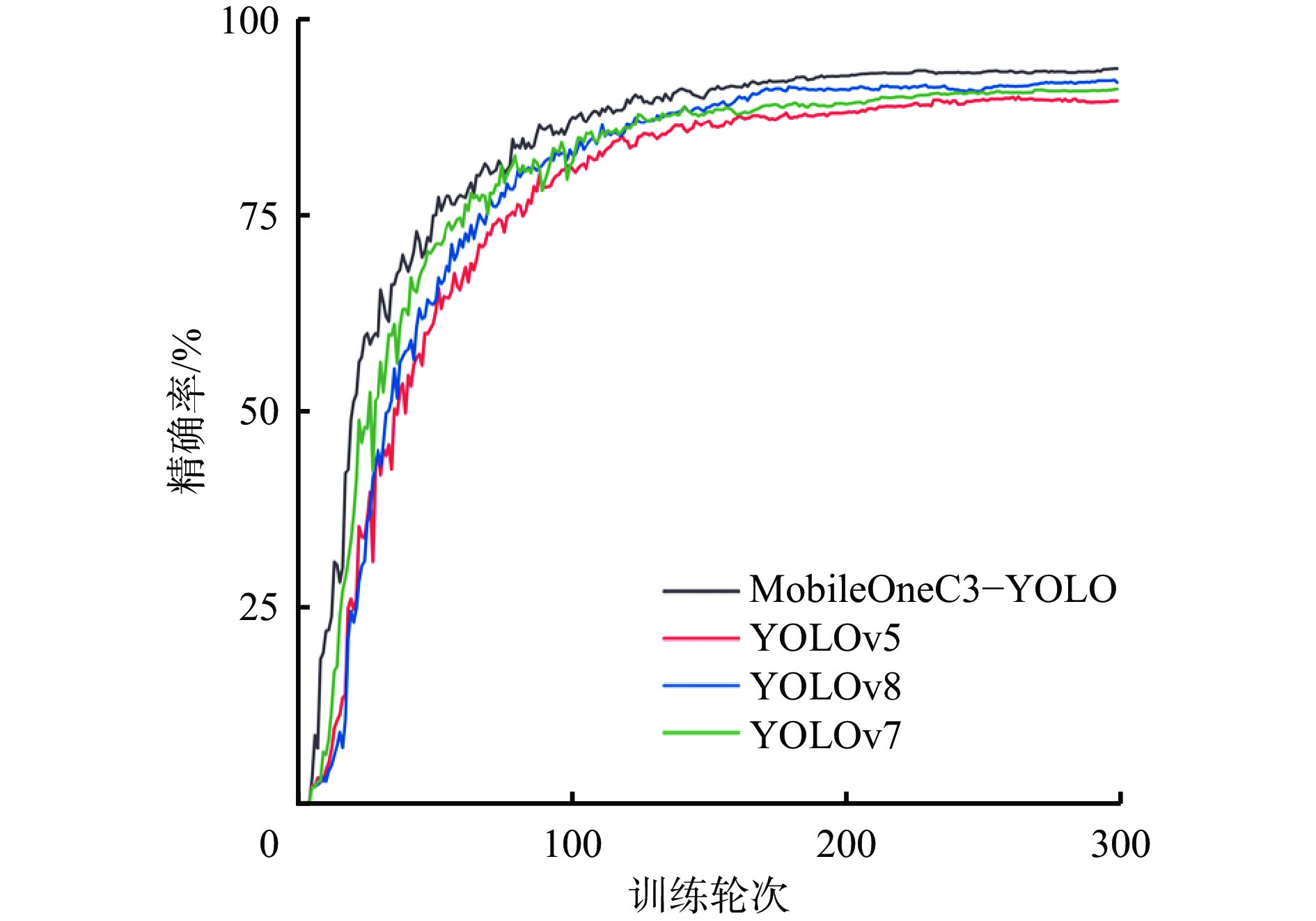
为验证MobileOneC3−YOLO模型的优势,基于煤矿关键岗位人员目标检测数据集,将其与YOLOv5、YOLOv7和YOLOv8模型进行对比,结果如图11所示。可看出,迭代200轮后,模型精确率逐渐趋于稳定,MobileOneC3−YOLO模型的精确率最终稳定在93.7%,训练效果优于其他模型。
模型检测精确率、参数量和单帧图像推理耗时对比见表2。可看出,MobileOneC3−YOLO模型参数量为2.51×107个,较YOLOv5,YOLOv7,YOLOv8分别降低19.5%,32.5%,42.4%;MobileOneC3−YOLO模型的单帧图像推理耗时为0.020 8 s,推理速度较YOLOv5,YOLOv7,YOLOv8分别提高47.3%,52.4%,56.2%。MobileOneC3−YOLO模型的精度最高,同时参数量最少,显著提升了检测效率。
表 2 人员检测模型性能Table 2. Personnel detection model performance模型 精确率/% 参数量/107个 单帧图像推理耗时/s YOLOv5 89.6 3.12 0.0395 YOLOv7 91.1 3.72 0.0437 YOLOv8 91.9 4.36 0.0475 MobileOneC3−YOLO 93.7 2.51 0.0208 为进一步验证轻量化优化效果,进行消融实验。以YOLOv7作为基础模型,评估MobileOne与 C3对网络主干和头部的优化效果。人员检测模型消融实验结果见表3。可看出,单独使用MobileOne优化主干网络后,模型精确率下降0.3%,参数量减少21.2%,推理速度提高21.5%;单独使用C3优化头部网络后,模型精确率和推理速度分别提高0.2%和17.8%,参数量减少27.1%;综合使用MobileOne和C3优化网络结构后,模型在维持高精度的同时,参数量和单帧图像推理耗时分别降至2.51×107个和0.020 8 s,性能提升明显,轻量化改进效果显著。
表 3 人员检测模型消融实验结果Table 3. Ablation experiment results of personnel detection model改进策略 精确率/% 参数量/107个 单帧图像推理耗时/s MobileOne C3 × × 91.1 3.72 0.043 7 √ × 90.8 2.93 0.034 3 × √ 92.1 2.71 0.035 9 √ √ 93.7 2.51 0.020 8 3.4 人员锁定模型性能分析
为评估基于ByteTrack的人员跟踪方法的有效性,以MobileOneC3−YOLO模型的检测结果作为输入,采用多目标跟踪数据集MOT17[18]对SORT[19]、DeepSort[20]和ByteTrack进行对比实验,结果见表4。
表 4 跟踪算法对比实验结果Table 4. Comparison experiment results of tracking algorithms算法 IDF1/% MOTA/% FP FN 帧率/(帧·s−1) SORT 75.5 73.6 4 856 21 376 21.3 DeepSort 85.7 81.3 6 512 19 837 14.7 ByteTrack 88.1 85.5 5 539 13 557 29.6 从表4可看出,ByteTrack算法在跟踪任务中表现优异,其ID调和均值IDF1和多目标跟踪准确率MOTA分别达到88.1%和85.5%,同时因采用轻量化架构,推理帧率达到29.6帧/s。SORT算法虽然误跟踪目标数最小,但漏跟踪目标数过大,表明其在目标特征利用上存在不足。此外,SORT和DeepSort算法因采用高置信度检测框筛选策略,忽视低置信度检测框,导致性能不如ByteTrack算法。
采用ByteTrack算法对井口信把工、变电站值班人员、矿井提升机和绞车司机4个关键岗位人员进行锁定测试。每个关键岗位选取视频60段,每段2 min,共计240段,进行3轮测试。设置目标停留持续时间阈值为30 s,实验结果见表5。可看出,基于ByteTrack的关键岗位人员锁定模型总体锁定成功率为97.1%,平均成功锁定次数达58,有效实现了对关键岗位工作人员的跟踪锁定。
表 5 关键岗位人员锁定结果统计Table 5. Statistics on the key position personnel locking results关键岗位人员 成功锁定次数 平均成功
锁定次数总体锁定
成功率/%1轮 2轮 3轮 矿井提升机司机 60 59 60 59 97.10 绞车司机 59 60 57 58 变电站值班人员 58 60 59 58 井口信把工 59 58 60 58 煤矿关键岗位人员锁定效果如图12所示,模型可持续有效地跟踪锁定工作人员,同时避免对背景中无关人员的检测跟踪,排除了背景中无关人员对不安全行为识别的影响。
3.5 不安全行为识别模型性能分析
采用MS COCO2017[21]数据集对改进OpenPose模型进行评估。该数据集共包含123 287张图像,每张图像含有17个人体关键点标注。为进一步细化人体上身姿态信息,增加颈部关键点,使得每张图像包含18个人体关键点标注。不安全行为识别模型性能测试结果见表6。可看出,相较于OpenPose,改进OpenPose平均精确率下降2.4%,但模型内存减小至33.5 MiB,降幅达83.5%,在CPU和GPU上的单帧图像推理耗时分别减少74.7%和54.9%。这表明改进OpenPose在保证精度的基础上,显著提升了计算效率和推理速度。
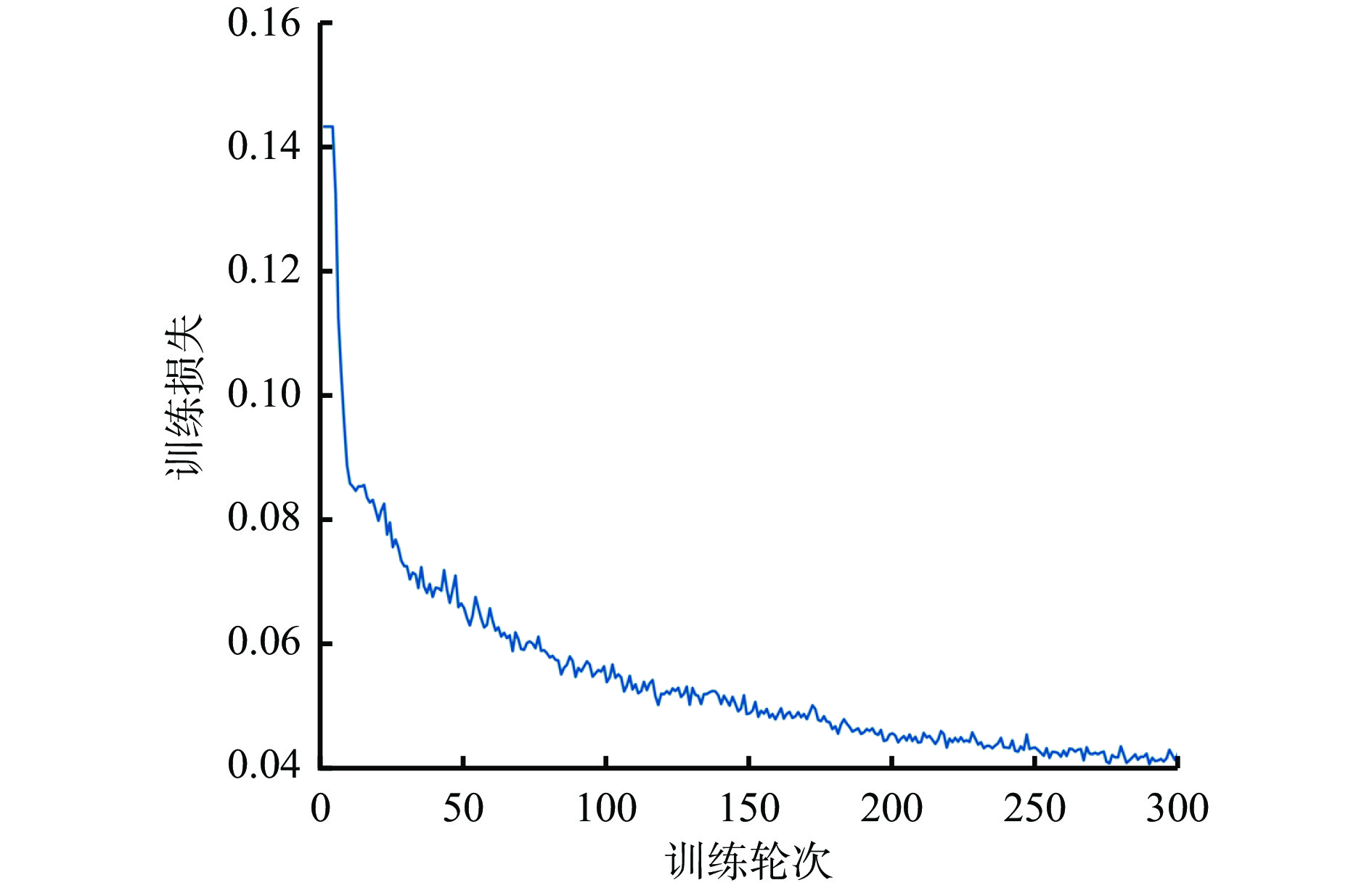
表 6 不安全行为识别模型性能测试结果Table 6. Performance test results of unsafe behaviors recognition model模型 AP/% 模型内存/MiB 单帧图像推理耗时/s CPU:12900K GPU:3090 OpenPose 74.6 203.8 0.8326 0.0573 改进OpenPose 72.8 33.5 0.2103 0.0258 完成人体关键点提取后,采用ST−GCN模型对煤矿关键岗位人员的不安全行为进行识别。采用煤矿关键岗位人员不安全行为数据集进行模型训练,设置模型输入总帧数为200, batch size为32,类别数为4,初始学习率为0.002。模型损失函数曲线如图13所示。
由图13可看出,随着训练轮次增加,ST−GCN模型的损失值持续下降,在250次迭代后趋于平稳,最终稳定在0.042 5,此时精确率为87.5%。
为验证轻量化煤矿关键岗位人员不安全行为识别方法的有效性,进行消融实验。以ByteTrack和ST−GCN为基础,考察目标检测模型和姿态估计模型对疲劳睡岗、离岗、侧身交谈和玩手机4种不安全行为识别精确率和速度的影响。不安全行为识别模型消融实验结果见表7。
表 7 不安全行为识别模型消融实验结果Table 7. Ablation experiment results of unsafe behaviors recognition model改进策略 精确率/% 帧率/(帧·s−1) YOLOv7+OpenPose 91.8 7.1 YOLOv7+改进OpenPose 92.1 12.5 MobileOneC3−YOLO+OpenPose 91.6 13.7 MobileOneC3−YOLO+改进OpenPose 93.5 18.6 可看出,MobileOneC3−YOLO+改进OpenPose的组合对4种不安全行为的识别精确率达到93.5%,同时大幅提升了检测速度,帧率达到18.6帧/s。这表明本文方法在保证高精确率的同时,通过轻量化改进大幅降低了时间复杂度,显著提升了检测效率,有利于及时地对不安全行为进行预警和干预。
煤矿关键岗位人员不安全行为识别效果如图14所示。可看出本文提出的不安全行为识别模型能够准确提取人员姿态信息,对疲劳睡岗、离岗、侧身交谈和玩手机4种不安全行为能够精准识别。
![]() 图 14 煤矿关键岗位人员不安全行为识别效果Figure 14. Unsafe behaviors recognition effect of key position personnel in coal mines
图 14 煤矿关键岗位人员不安全行为识别效果Figure 14. Unsafe behaviors recognition effect of key position personnel in coal mines4. 结论
1) 采用MobileOne与C3对 YOLOv7的主干与头部网络进行轻量化改进设计,显著提升了模型的检测效率,MobileOneC3−YOLO模型推理速度较YOLOv7提升了52%。
2) 引入ByteTrack算法实现人员锁定,锁定成功率达97.1%,有效排除了背景中无关人员的干扰。
3) 为了提高OpenPose对骨架特征的提取效率,采用MobileNetv2优化OpenPose特征提取网络,优化后模型内存需求降低了170.3 MiB,在CPU与GPU上的推理速度分别提升了74.7%和54.9%。
4) 不安全行为识别实验结果表明,基于改进YOLOv7和ByteTrack的煤矿关键岗位人员不安全行为识别方法对疲劳睡岗、离岗、侧身交谈和玩手机4种不安全行为的识别精确率达93.5%,检测速度达18.6帧/s。
-
![]()
图 14 煤矿关键岗位人员不安全行为识别效果
Figure 14. Unsafe behaviors recognition effect of key position personnel in coal mines
表 1 评价指标
Table 1 Evaluation indexes
评价指标 定义 计算公式 Precision(↑) 精确率 $ \dfrac{{{\mathrm{TP}}}}{{{\mathrm{TP}} + {\mathrm{FP}}}}$ Params(↓) 参数量 — AP(↑) 关键点相似度为[0.50,0.55,···,0.95]时
10个位置的平均精确率— 帧率(↑) 每秒处理的帧数 $ \dfrac{{总帧数}}{{时间}} $ MOTA(↑) 多目标跟踪准确率 $ 1 - \dfrac{{{\mathrm{FN}} + {\mathrm{FP}} + {\mathrm{IDSW}}}}{{{\mathrm{GT}}}}$ IDF1(↑) ID调和均值 $ \dfrac{{2{\mathrm{TP}}}}{{2{\mathrm{TP}} + {\mathrm{FP }}+ {\mathrm{FN}}}}$ FP(↓) 误跟踪目标数 — FN(↓) 漏跟踪目标数 —  下载: 导出CSV
下载: 导出CSV
表 2 人员检测模型性能
Table 2 Personnel detection model performance
模型 精确率/% 参数量/107个 单帧图像推理耗时/s YOLOv5 89.6 3.12 0.0395 YOLOv7 91.1 3.72 0.0437 YOLOv8 91.9 4.36 0.0475 MobileOneC3−YOLO 93.7 2.51 0.0208
下载: 导出CSV
表 3 人员检测模型消融实验结果
Table 3 Ablation experiment results of personnel detection model
改进策略 精确率/% 参数量/107个 单帧图像推理耗时/s MobileOne C3 × × 91.1 3.72 0.043 7 √ × 90.8 2.93 0.034 3 × √ 92.1 2.71 0.035 9 √ √ 93.7 2.51 0.020 8
下载: 导出CSV
表 4 跟踪算法对比实验结果
Table 4 Comparison experiment results of tracking algorithms
算法 IDF1/% MOTA/% FP FN 帧率/(帧·s−1) SORT 75.5 73.6 4 856 21 376 21.3 DeepSort 85.7 81.3 6 512 19 837 14.7 ByteTrack 88.1 85.5 5 539 13 557 29.6
下载: 导出CSV
表 5 关键岗位人员锁定结果统计
Table 5 Statistics on the key position personnel locking results
关键岗位人员 成功锁定次数 平均成功
锁定次数总体锁定
成功率/%1轮 2轮 3轮 矿井提升机司机 60 59 60 59 97.10 绞车司机 59 60 57 58 变电站值班人员 58 60 59 58 井口信把工 59 58 60 58
下载: 导出CSV
表 6 不安全行为识别模型性能测试结果
Table 6 Performance test results of unsafe behaviors recognition model
模型 AP/% 模型内存/MiB 单帧图像推理耗时/s CPU:12900K GPU:3090 OpenPose 74.6 203.8 0.8326 0.0573 改进OpenPose 72.8 33.5 0.2103 0.0258
下载: 导出CSV
表 7 不安全行为识别模型消融实验结果
Table 7 Ablation experiment results of unsafe behaviors recognition model
改进策略 精确率/% 帧率/(帧·s−1) YOLOv7+OpenPose 91.8 7.1 YOLOv7+改进OpenPose 92.1 12.5 MobileOneC3−YOLO+OpenPose 91.6 13.7 MobileOneC3−YOLO+改进OpenPose 93.5 18.6
下载: 导出CSV
-
[1] 李琰,刘珍,陈南希. 基于矿工大数据的不安全行为主题挖掘与语义分析[J]. 煤矿安全,2023,54(9):254-257. LI Yan,LIU Zhen,CHEN Nanxi. Topic mining and semantic analysis of unsafe behavior based on miner big data[J]. Safety in Coal Mines,2023,54(9):254-257.
[2] 黄辉,张雪. 煤矿员工不安全行为研究综述[J]. 煤炭工程,2018,50(6):123-127. HUANG Hui,ZHANG Xue. Review of research on unsafe behavior of miners[J]. Coal Engineering,2018,50(6):123-127.
[3] 丁恩杰,俞啸,夏冰,等. 矿山信息化发展及以数字孪生为核心的智慧矿山关键技术[J]. 煤炭学报,2022,47(1):564-578. DING Enjie,YU Xiao,XIA Bing,et al. Development of mine informatization and key technologies of intelligent mines[J]. Journal of China Coal Society,2022,47(1):564-578.
[4] 沈铭华,马昆,杨洋,等. AI智能视频识别技术在煤矿智慧矿山中的应用[J]. 煤炭工程,2023,55(4):92-97. SHEN Minghua,MA Kun,YANG Yang,et al. Application of AI identification technology in intelligent coal mine[J]. Coal Engineering,2023,55(4):92-97.
[5] 刘浩,刘海滨,孙宇,等. 煤矿井下员工不安全行为智能识别系统[J]. 煤炭学报,2021,46(增刊2):1159-1169. LIU Hao,LIU Haibin,SUN Yu,et al. Intelligent recognition system for unsafe behavior of coal mine employees underground[J]. Journal of China Coal Society,2021,46(S2):1159-1169.
[6] 温廷新,王贵通,孔祥博,等. 基于迁移学习与残差网络的矿工不安全行为识别[J]. 中国安全科学学报,2020,30(3):41-46. WEN Tingxin,WANG Guitong,KONG Xiangbo,et al. Identification of miners' unsafe behaviors based on transfer learning and residual network[J]. China Safety Science Journal,2020,30(3):41-46.
[7] 李占利,权锦成,靳红梅. 基于3D−Attention与多尺度的矿井人员行为识别算法[J]. 国外电子测量技术,2023,42(7):95-104. DOI: 10.3969/j.issn.1002-8978.2023.07.014 LI Zhanli,QUAN Jincheng,JIN Hongmei. Mine personnel behavior recognition algorithm based on 3D−Attention and multi-scale[J]. Foreign Electronic Measurement Technology,2023,42(7):95-104. DOI: 10.3969/j.issn.1002-8978.2023.07.014
[8] 王宇,于春华,陈晓青,等. 基于多模态特征融合的井下人员不安全行为识别[J]. 工矿自动化,2023,49(11):138-144. WANG Yu,YU Chunhua,CHEN Xiaoqing,et al. Recognition of unsafe behaviors of underground personnel based on multi modal feature fusion[J]. Journal of Mine Automation,2023,49(11):138-144.
[9] WANG C-Y,BOCHKOVSKIY A,LIAO H-Y M. YOLOv7:trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition,Vancouver,2023:7464-7475.
[10] VASU P K A,GABRIEL J,ZHU J,et al. An improved one millisecond mobile backbone[EB/OL]. [2024-02-20]. https://arxiv.org/pdf/2206.04040.pdf.
[11] 黄家才,赵雪迪,高芳征,等. 基于改进YOLOv5s的草莓多阶段识别检测轻量化算法[J]. 农业工程学报,2023,39(21):181-187. DOI: 10.11975/j.issn.1002-6819.202307186 HUANG Jiacai, ZHAO Xuedi, GAO Fangzheng, et al. Recognizing and detecting the strawberry at multi-stages using improved lightweight YOLOv5s[J]. Transactions of the Chinese Society of Agricultural Engineering,2023,39(21):181-187. DOI: 10.11975/j.issn.1002-6819.202307186
[12] ZHANG Yifu,SUN Peize,JIANG Yi,et al. ByteTrack:multi-object tracking by associating every detection box[EB/OL]. [2024-02-20]. https://arxiv.org/abs/2110.06864v1.
[13] CAO Zhe,SIMON T,WEI S-E,et al. Realtime multi-person 2D pose estimation using part affinity fields[C]. IEEE Conference on Computer Vision and Pattern Recognition,Honolulu,2017:1302-1310.
[14] SIMONYAN K,ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2024-02-20]. https://arxiv.org/pdf/1409.1556.pdf.
[15] SANDLER M,HOWARD A,ZHU Menglong,et al. MobileNetV2:inverted residuals and linear bottlenecks[EB/OL]. [2024-02-20]. http://arxiv.org/pdf/1801.04381.pdf.
[16] YAN Sijie,XIONG Yuanjun,LIN Dahua. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]. AAAI Conference on Artificial Intelligence,New Orleans,2018:5361-5368.
[17] BAI Shaojie,KOLTER J Z,KOLTUN V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling[EB/OL]. [2024-02-20]. https://arxiv.org/pdf/1803.01271.pdf.
[18] MILAN A,LEAL-TAIXÉ L,REID I,et al. MOT16:a benchmark for multi-object tracking[EB/OL]. [2024-02-20]. https://arxiv.org/pdf/1603.00831.pdf.
[19] BEWLEY A,GE Zongyuan,OTT L,et al. Simple online and realtime tracking[C]. IEEE International Conference on Image Processing,Phoenix,2016:3464-3468.
[20] WOJKE N,BEWLEY A,PAULUS D. Simple online and realtime tracking with a deep association metric[C]. IEEE International Conference on Image Processing,Beijing,2017:3645-3649.
[21] LIN T−Y,MAIRE M,BELONGIE S,et al. Microsoft COCO:common objects in context[EB/OL]. [2024-02-20]. https://www.microsoft.com/en-us/research/wp-content/uploads/2014/09/LinECCV14coco.pdf.
-
期刊类型引用(3)
1. 贺纪桦,张月峰,刘悦云. 基于改进YOLOv8的智慧工厂工人不规范行为检测. 制造技术与机床. 2025(02): 185-193 .  百度学术
百度学术
2. 周李兵,于政乾,卫健健,蒋雪利,叶柏松,赵叶鑫,杨斯亮. 矿用无人驾驶车辆行人检测技术研究. 工矿自动化. 2024(10): 29-37 . 本站查看
3. 班国邦,付磊,蒋理,杜昊,黎安俊,何雨昱,周骏超. 基于图像筛选的两阶段复杂作业人员行为动态风险辨识. 电力大数据. 2024(08): 58-69 . 百度学术
其他类型引用(1)



计量
- 文章访问数: 318
- HTML全文浏览量: 136
- PDF下载量: 61
- 被引次数: 4
