
Multi-target detection of underground personnel based on an improved YOLOv8n model
-
摘要:
针对井下危险区域人员监测视频存在光照不均匀、目标尺度不一致、遮挡等复杂情况,基于YOLOv8n网络结构,提出一种改进的井下人员多目标检测算法—YOLOv8n−MSMLAS。该算法对YOLOv8n的Neck层进行改进,添加多尺度空间增强注意力机制(MultiSEAM),以增强对遮挡目标的检测性能;在C2f模块中引入混合局部通道注意力(MLCA)机制,构建C2f−MLCA模块,以融合局部和全局特征信息,提高特征表达能力;在Head层检测头中嵌入自适应空间特征融合(ASFF)模块,以增强对小尺度目标的检测性能。实验结果表明:① 与Faster R−CNN,SSD,RT−DETR,YOLOv5s,YOLOv7等主流模型相比,YOLOv8n−MSMLAS综合性能表现最佳,mAP@0.5和mAP@0.5:0.95分别达到93.4%和60.1%,FPS为80.0帧/s,参数量为5.80×106个,较好平衡了模型的检测精度和复杂度。② YOLOv8n−MSMLAS在光照不均、目标尺度不一致、遮挡等条件下表现出较好的检测性能,适用于现场检测。
-
关键词:
- 煤矿井下危险区域 /
- 井下人员多目标检测 /
- YOLOv8n /
- 多尺度空间增强注意力机制 /
- 自适应空间特征融合 /
- 轻量化混合局部通道注意力机制
Abstract:This study aims to address the complex challenges in monitoring underground personnel in hazardous areas, including uneven lighting, target scale inconsistency, and occlusion. An innovative multi-target detection algorithm, YOLOv8n-MSMLAS, was proposed based on the YOLOv8n network structure. The algorithm modified the Neck layer by incorporating a Multi-Scale Spatially Enhanced Attention Mechanism (MultiSEAM) to enhance the detection of occluded targets. Furthermore, a Hybrid Local Channel Attention (MLCA) mechanism was introduced into the C2f module to create the C2f-MLCA module, which fused local and global feature information, thereby improving feature representation. An Adaptive Spatial Feature Fusion (ASFF) module was embedded in the Head layer to boost detection performance for small-scale targets. Experimental results demonstrated that YOLOv8n-ASAM outperformed mainstream models such as Faster R-CNN, SSD, RT-DETR, YOLOv5s, and YOLOv7 in terms of overall performance, achieving mAP@0.5 and mAP@0.5: 0.95 of 93.4% and 60.1%, respectively,with a speed of 80.0 frames per second,the parameter is 5.80×106, effectively balancing accuracy and complexity. Moreover, YOLOv8n-ASAM exhibited superior performance under uneven lighting, target scale inconsistency, and occlusion, making it well-suited for real-world applications.
-
0. 引言
煤矿井下作业环境复杂多变,存在诸多安全隐患,一些危险区域如瓦斯等有害气体超标区域、重要设备区域、绞车运行的斜巷等,一般禁止人员进入。由于井下环境的特殊性,依赖人工查看危险区域监控视频的告警方式不能达到理想效果。随着深度学习技术的不断成熟,采用基于深度学习的计算机视觉算法对井下危险区域的人员进行实时监测,已成为确保煤矿安全生产的重要手段。
目前,煤矿井下广泛采用区域卷积神经网络(Region-based Convolutional Neural Networks,R−CNN)[1]、Fast R−CNN[2]、Faster R−CNN[3]、单次检测多框检测器(Single Shot MultiBox Detector,SSD)[4]、YOLO系列模型[5]等,对井下危险区域的人员进行实时监测。相较于R−CNN系列模型和SSD模型,YOLO系列模型以其出色检测性能被广泛用于煤矿井下目标检测。文献[6-9]基于改进YOLOv4模型对井下行人进行检测,解决了井下工作面光照不均、煤尘干扰、遮挡等问题,有效提高了检测精度。文献[10-13]对YOLOv5进行改进,实现了多尺度特征快速捕捉,在模型参数量大幅减少的情况,提升了井下人员的检测精度,并实现了实时检测。文献[14]提出了一种基于改进FM−YOLOv7的矿井人员安全帽检测方法,实现了对井下小目标的精准检测。文献[15-18]通过改进YOLOv8系列模型的不同模块,在对模型轻量化的同时,增强了图像多尺度目标特征的提取与融合能力,提升了模型的检测精度和效率。文献[19]提出了一种重新参数化YOLO(Rep−YOLO)算法,结合K−means++聚类锚帧和交叉垂直通道注意力机制(Criss-Cross-Vertical with Channel Attention,CVCA),提高了复杂环境下煤矿作业人员检测的准确率和速度。上述研究在一定程度上提升了井下目标检测的精度和效率,但难以满足煤矿复杂场景下多目标检测的实际需求,且模型的轻量化、鲁棒性和泛化性还有待进一步提升。
针对上述问题,本文基于YOLOv8n网络结构,结合注意力和尺度融合机制提出了改进的目标检测算法—YOLOv8n−MSMLAS。该算法通过添加多尺度空间增强注意力机制(Multi−Scale Spatially Enhanced Attention Module,MultiSEAM)[20],以增强对遮挡目标的检测性能;在C2f中结合轻量化混合局部通道注意力(Mixed Local Channel Attention,MLCA)[21]机制,融合局部和全局信息,削弱光照不均和多目标稀疏分布对检测精度的影响;通过引入自适应空间特征融合(Adaptively Spatial Feature Fusion, ASFF)[22]模块,增强检测头对小尺度目标的检测能力。
1. YOLOv8n−MSMLAS模型
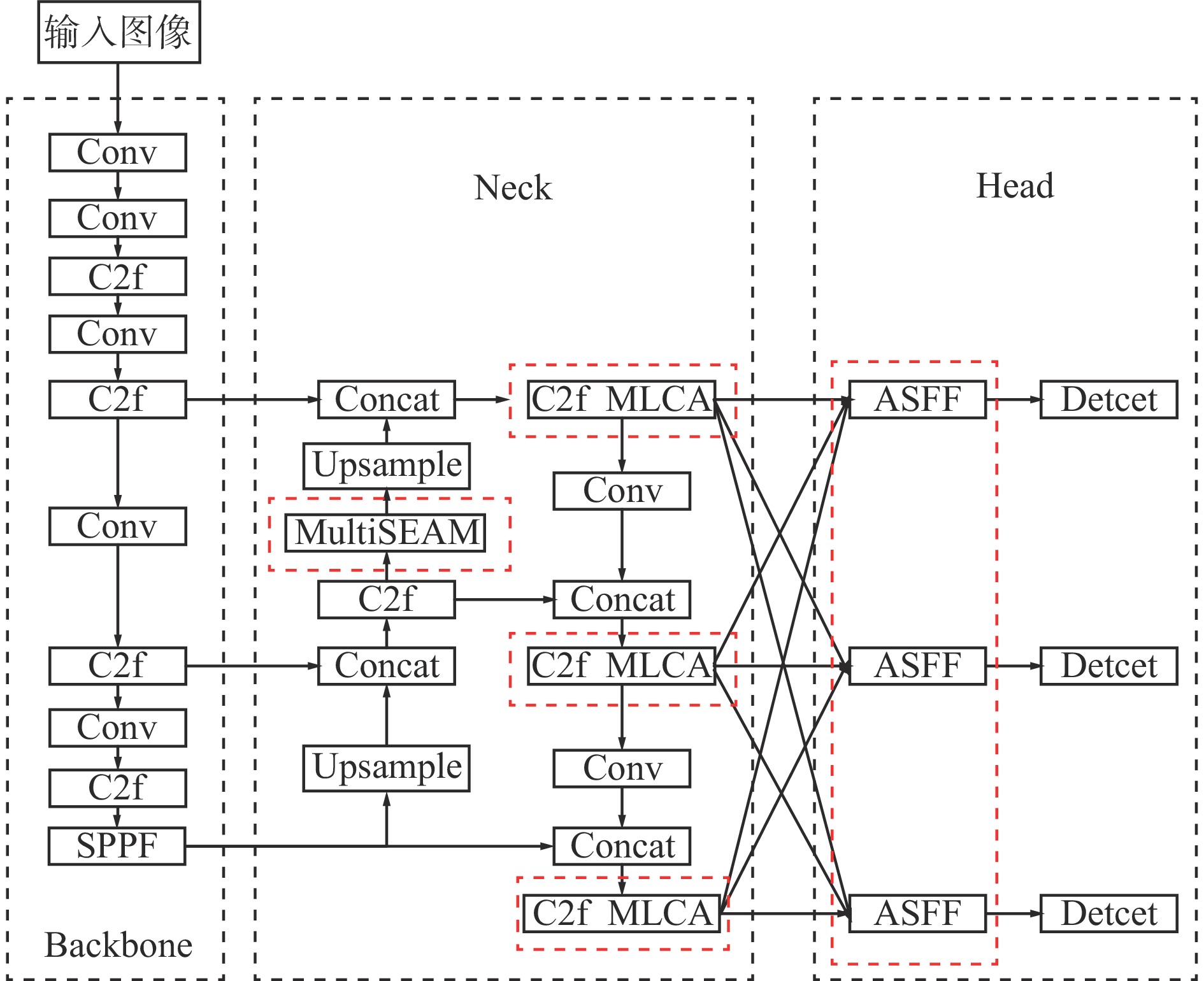
YOLOv8n−MSMLAS网络结构如图1所示。
1.1 MultiSEAM机制
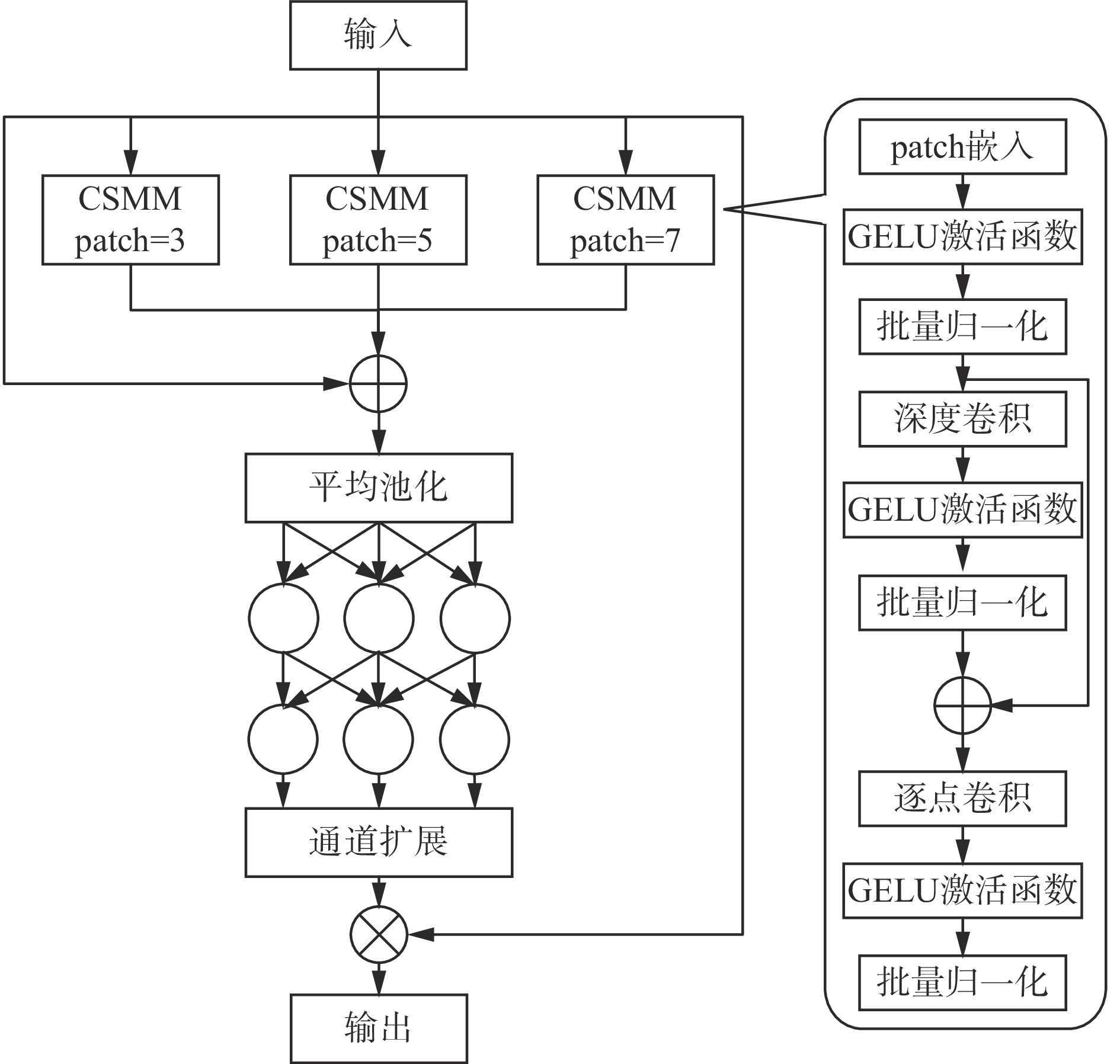
井下各个作业场景空间有限、人员密集,且存在多种施工设备,井下监控摄像机因为视角固定,在检测人员时经常会出现由于遮挡而检测不准确的问题。为了解决这一问题,在YOLOv8n模型的Neck部分引入了MultiSEAM(图2),在多尺度下捕捉并融合Backbone中提取的含深层语义特征的全局信息,使模型能够更好地理解遮挡和未遮挡目标之间的关系,并为后续浅层空间特征融合作准备,以解决在处理遮挡目标时深层特征局部信息缺失的问题。
MultiSEAM通过增强对未遮挡区域的响应,解决因遮挡导致的检测性能下降问题。其核心组件通道与空间混合模块(Channel and Spatial Mixing Module,CSMM)采用不同尺度的卷积核并行处理输入特征,旨在有效捕捉多尺度的特征信息。每个CSMM模块通过深度可分离卷积和残差连接提取通道特征,有效减少了参数量,保证特征表达的丰富性。单独处理通道可能忽略通道间的信息交互,因此采用1×1点对点卷积来整合通道信息,增强通道之间的联系。特征经CSMM模块输出后,利用全局平均池化缩减空间维度,并通过2层全连接网络融合通道信息,确保通道间的紧密关联。最终,通过通道扩展操作整合多尺度特征,有效降低了遮挡场景下的检测误差。
1.2 MLCA机制
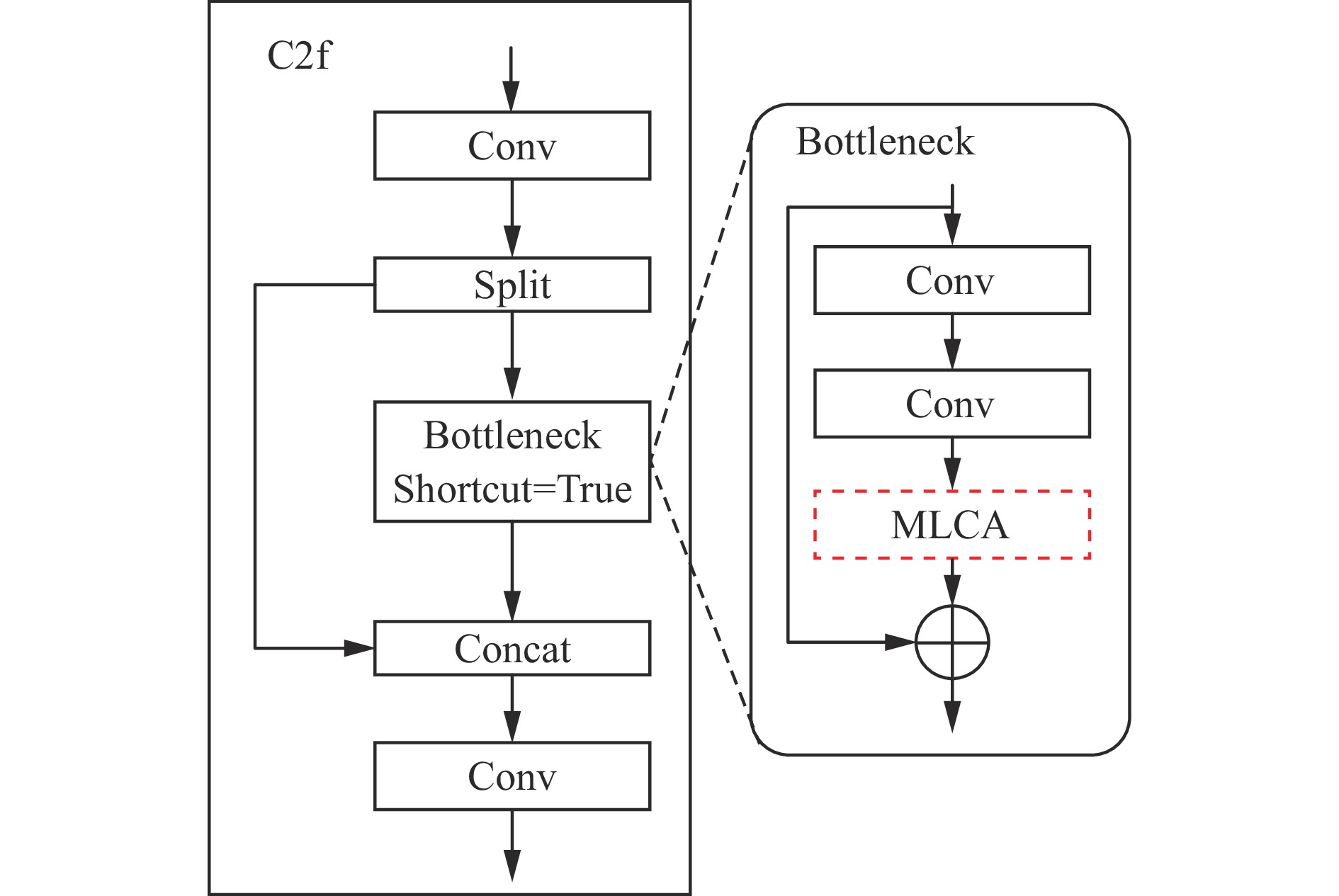
由于煤矿井下作业环境光照不足,且矿井各作业区提供的强光源与矿工佩戴的头灯共同照明,使得井下环境的光线非常复杂,不同区域亮度差异明显。部分区域光照过强,而其他区域则较为昏暗,这种光照不均导致目标检测模型难以准确捕捉目标的细节。此外,人员目标呈现分布不均匀的情况,有些区域人员密集,而有些区域呈稀疏分布,这就要求检测模型具备同时处理全局信息和精确捕捉局部细节的能力,有效检测分散的目标。为解决上述问题,在YOLOv8n模型Neck部分C2f模块的Bottleneck中引入轻量化MLCA机制,如图3所示。
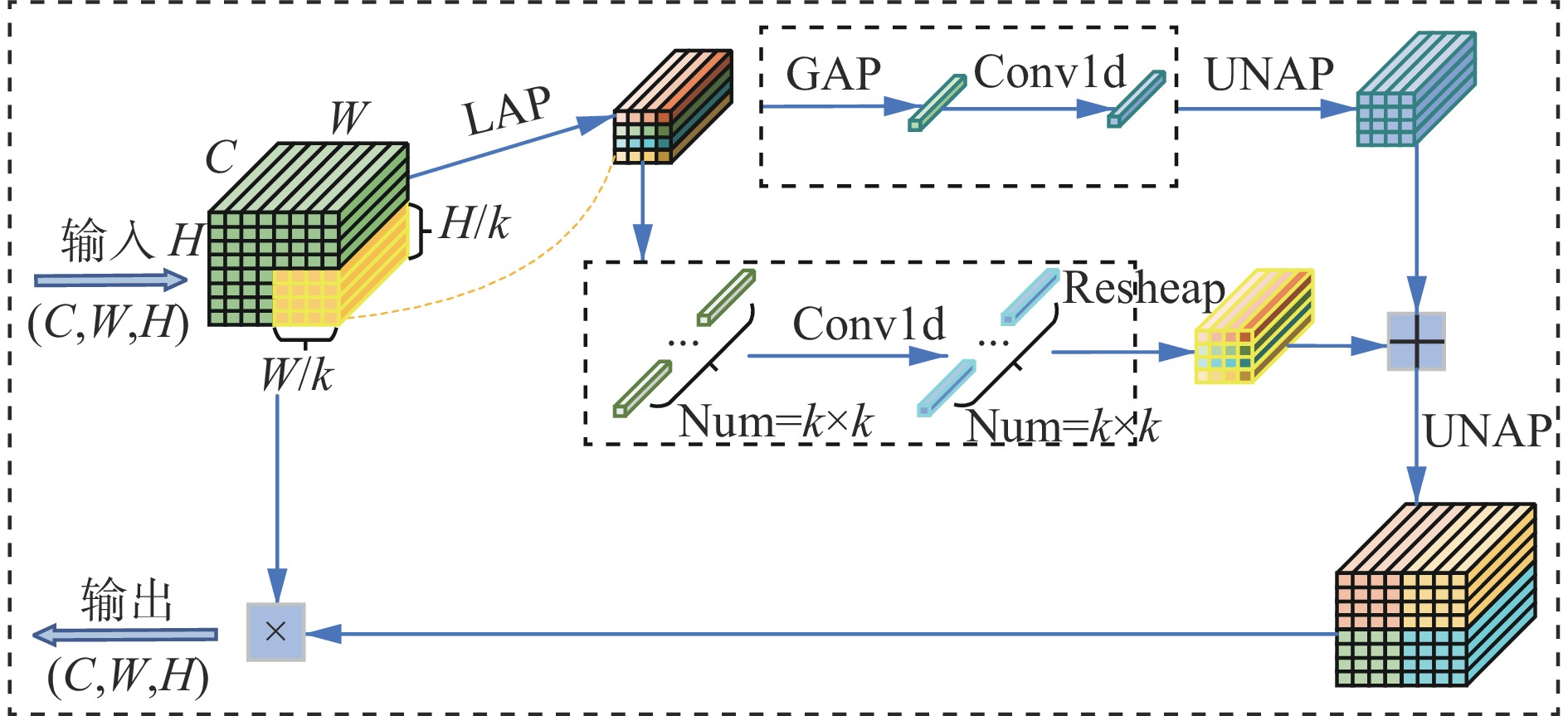
MLCA机制在不增加模型过多参数情况下融合局部与全局特征、通道与空间信息,有效削弱光照不均和目标分布多而稀疏对检测的影响,增强模型对关键区域的感知能力,其结构如图4所示。其中,C为输入输出特征图的通道数,H为输入输出特征图的高度,W为输入输出特征图的宽度,k为池化操作的窗口尺寸。
MLCA机制通过局部平均池化(Local Average Pooling,LAP)和全局平均池化(Global Average Pooling,GAP)处理特征图,分别捕捉局部细节和全局信息,以解决光照不均问题。LAP聚焦于低光区域,提升模型对细节的感知能力,而GAP则通过提取全局关键特征,减少强光区域的背景噪声干扰。通过融合这2类特征,有效削弱了光照不均对检测的负面影响。此外,针对目标多而稀疏的问题,MLCA利用1D卷积对局部与全局特征进行通道压缩,保留关键信息,并融合全局上下文和局部细节,提升模型对稀疏分布目标的检测能力。通过反池化操作,特征图恢复到原始空间分辨率,增强了对显著区域的关注,提高了对稀疏多目标的检测精度,并有效抑制了复杂背景的干扰。
1.3 ASFF模块
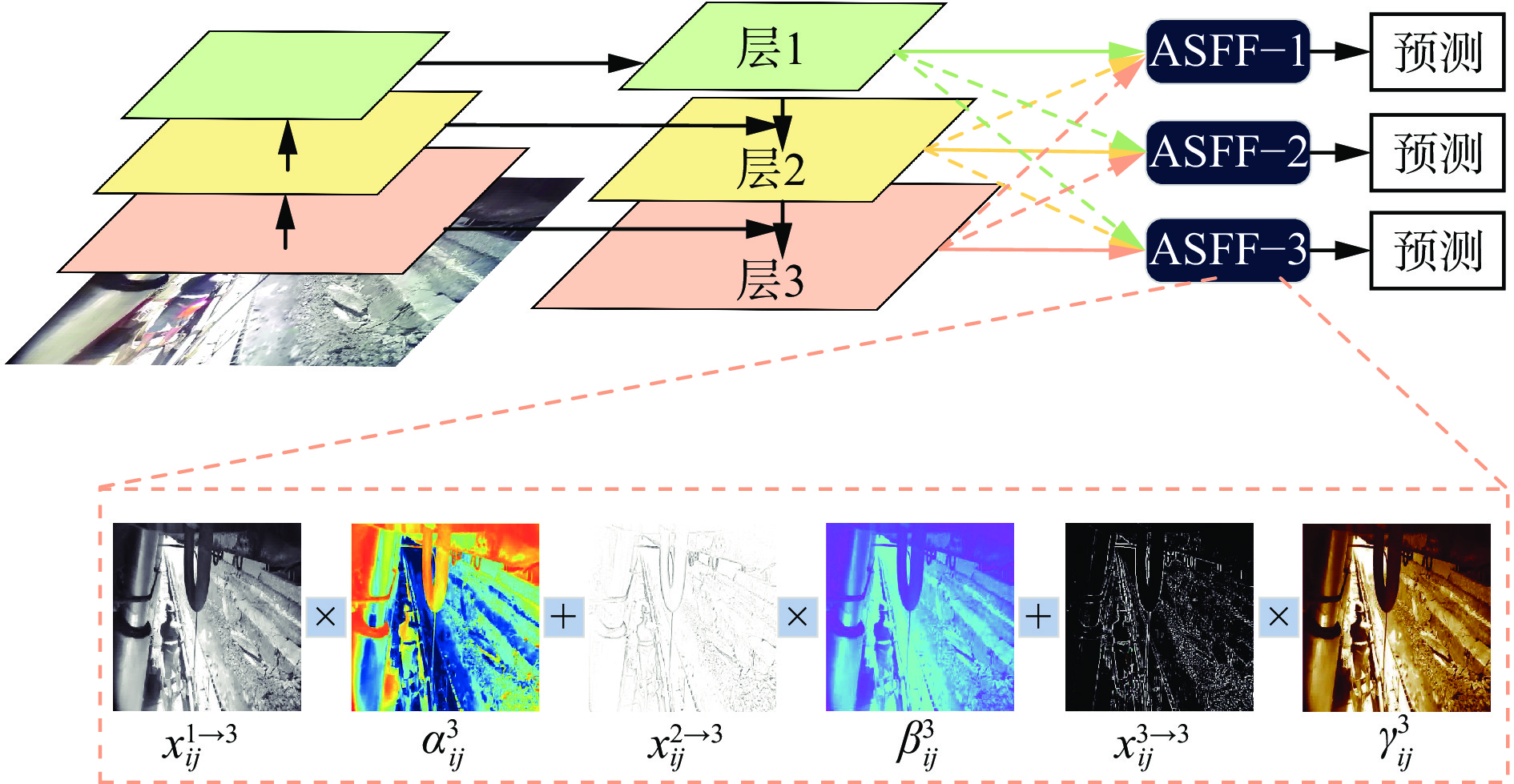
在煤矿井下环境中,由于监控设备采集人员目标时,距离远近不同,导致图像中人员目标尺度不同,此问题在目标检测模型中常引发小尺度目标漏检或检测精度下降。针对这一问题,在YOLOv8n模型的检测头中引入了ASFF模块。ASFF通过自适应融合不同尺度的特征图,解决特征层之间尺度不一致的问题,并根据位置自适应调整各层特征图的权重,确保输出的多尺度特征对检测最有利,从而提高检测精度,其结构如图5所示。
在自适应融合阶段,以第3个融合层ASFF−3为例进行融合操作。假设$ x_{ij}^{1 \to 3} $,$ x_{ij}^{2 \to 3} $,$ x_{ij}^{3 \to 3} $分别为来自层1、层2和层3的输出特征,通过将每层的输出特征与该融合层的权重参数$\alpha _{ij}^3$,$ \beta _{ij}^3 $,$ \gamma _{ij}^3 $相乘并相加,得到新的融合特征。这种融合方式使模型能够兼顾远近目标的细节,不再因人员目标尺度不同而漏检。
$$ {{y}}_{ij}^l = \alpha _{ij}^l x_{ij}^{1 \to l} + \beta _{ij}^l x_{ij}^{2 \to l} + \gamma _{ij}^l x_{ij}^{3 \to l} $$ (1) 式中:$y_{ij}^l$为经第$l$个融合层融合后的特征图在位置$(i,j)$处特征值,l=1,2,3;$\alpha _{ij}^l$,$ \beta _{ij}^l $,$ \gamma _{ij}^l $为第$l$个融合层中位置$ (i, j) $处权重参数;$ x_{ij}^{1 \to l} $,$ x_{ij}^{2 \to l} $,$ x_{ij}^{3 \to l} $分别为第$l$个融合层中来自不同层的输入特征在位置$ (i, j) $处特征值。
首先,应用1×1卷积操作对不同尺度(层1—层3)的特征图进行通道压缩,提取出与每个尺度特征图相关的权重信息。然后,将得到的各尺度权重参数进行拼接,形成一个综合的权重向量。最后,使用Softmax函数对综合权重进行归一化,得到最终的权重($\alpha _{ij}^l$,$ \beta _{ij}^l $,$ \gamma _{ij}^l $)分布。这个归一化后的权重决定了不同尺度特征图在最终融合时的相对重要性。该过程确保了融合后的特征图能够自适应地处理不同位置的人员目标,避免因尺度差异导致检测性能下降,提升了模型的鲁棒性和准确性。
$$ \alpha _{ij}^l = \frac{{\exp (\lambda _{\alpha ij}^l)}}{{\exp (\lambda _{\alpha ij}^l) + \exp ({\lambda _{\beta ij}^l} )+ \exp (\lambda _{\gamma ij}^l)}} $$ (2) 式中$ \exp (\lambda _{aij}^l) $,$ \exp (\lambda _{\beta ij}^l) $,$ \exp (\lambda _{\gamma ij}^l) $为权重参数的未归一化值。
2. 实验结果及分析
2.1 数据集采集与标注
实验数据由2个部分组成,一部分来自于井下人员作业视频提取关键帧生成的图像,一部分来自于DsLMF+公开数据集[23]中的井下人员图像。初始数据集共计652张图像(425张来自井下视频,227张来自DsLMF+公开数据集),既包括单个人员的简易场景,也涵盖多个人员同时出现、光照不均匀、遮挡等复杂作业环境,数据集部分样本如图6所示。
为更好地适应煤矿井下光照不均、人员目标尺度差异大等特点,采用水平翻转、中心裁剪、对比度调整及添加椒盐噪声等方法(图7)对初始数据集进行数据增强操作,以提升模型的鲁棒性与泛化能力。通过这些处理,图像数量由652张扩增至1 850张。同时,将所有图像分辨率统一调整为640×640,以确保输入数据的一致性与后续训练过程的稳定性。最终将增强后的数据集划分为训练集(1 454张)、验证集(220张)和测试集(176张)。
2.2 实验环境及评价指标
为验证YOLOv8n−ASMS的性能,在Pytorch深度学习框架下进行实验验证,具体硬件和软件环境配置见表1,数据集处理部分均在本地计算机中完成,所有算法的训练、验证和测试均在AutoDL算力云平台上进行。YOLOv8n−MSMLAS模型参数设置:批次样本数为32,总迭代次数为200,初始学习率为0.01,数据加载线程数(works)为8,训练过程中采用了mosaic数据增强技术。
表 1 环境配置参数Table 1. Environmental configuration parameters环境 配置参数 CPU 12th Gen Intel(R) Core(TM) i7−12650H GPU RTX 3030 (24 GiB)运行环境 Python3.9,CUDA 11.8 深度学习框架 Pytorch 1.12.1 编程语言 Python 3.9.7 采用准确率、召回率、mAP@0.5、mAP@0.5:0.95、推理速度FPS和参数量作为评价指标。准确率表示模型预测的正样本中实际为正样本的比例。召回率反映了实际正样本中被成功检测出来的比例,即在所有真实存在的目标中,模型能正确识别的比例。mAP@0.5代表在交并比(Intersection-over- Union,IoU)阈值为0.50时的平均精度(Mean Average Precision, mAP)。mAP@0.5:0.95表示不同IoU阈值(从0.50到0.95,步长为0.05)上的平均精度值。推理速度指模型每秒处理的样本帧数,体现了模型的处理速度。参数量体现了模型的复杂程度。
2.3 消融实验
为了验证YOLOv8n−MSMLAS算法的有效性,本文在相同的训练策略下,对MultiSEAM,MLCA和ASFF 3种改进方法进行了消融实验,具体结果见表2。改进模型1为YOLOv8n+MLCA,改进模型2为YOLOv8n+MultiSEAM,改进模型3为YOLOv8n+ASFF,改进模型4为YOLOv8n+MLCA+MultiSEAM,改进模型5为YOLOv8n+MLCA+ASFF,改进模型6为YOLOv8n+MultiSEAM+ASFF,改进模型7为YOLOv8n+MLCA+MultiSEAM+ASFF。
表 2 消融实验结果Table 2. Ablation experiment results模型 MLCA MultiSEAM ASFF 准确率/% 召回率/% mAP@0.5/% mAP@0.5:0.95/% FPS/(帧·s−1) 参数量/106个 YOLOv8n × × × 91.7 87.2 92.0 59.0 128.2 3.01 改进模型1 √ × × 93.7 86.3 92.9 59.1 109.9 3.01 改进模型2 × √ × 96.5 86.2 92.5 58.4 108.7 4.42 改进模型3 × × √ 95.6 88.8 93.4 58.9 104.2 4.38 改进模型4 √ √ × 95.3 89.6 93.4 58.3 101.1 4.43 改进模型5 √ × √ 95.8 85.8 92.9 56.5 91.7 4.38 改进模型6 × √ √ 96.2 89.0 92.6 59.1 88.5 5.80 改进模型7 √ √ √ 97.0 87.3 93.4 60.1 80.0 5.80 从表2可看出,改进模型1的准确率较YOLOv8n提升了2%,mAP@0.5提高了0.9%。改进模型2的准确率较YOLOv8n提高了4.8%,mAP@0.5提升了0.5%。改进模型3的准确率、召回率、mAP@0.5较YOLOv8n分别提升了3.9%、1.6%和1.4%。改进模型4的准确率较YOLOv8n提升3.6%,mAP@0.5提高1.4%。改进模型5的准确率较YOLOv8n提升4.1%,mAP@0.5提高0.9%。改进模型6的准确率较YOLOv8n提升4.5%,mAP@0.5提高0.6%。改进模型7 的准确率较YOLOv8n提高了5.3%,mAP@0.5提升1.4%,mAP@0.5:0.95提升1.1%,召回率也提高了0.1%。综合来看,YOLOv8n−MSMLAS模型在检测精度方面较原YOLOv8n模型有了显著提升,尽管网络结构的改进导致了网络层数增加,使得参数量上升至5.80×106个,FPS下降为80.0帧/s,但仍能满足煤矿井下人员实时检测的要求。
2.4 对比实验
为进一步验证YOLOv8n−MSMLAS在矿井多场景下人员目标检测性能,将其与Faster R−CNN,SSD,RT−DETR,YOLOv5s,YOLOv7,YOLOv8n等主流目标检测算法进行比较,实验结果见表3。
表 3 对比实验结果Table 3. Comparison experiment results模型 mAP@0.5/% mAP@0.5:0.95/% FPS/(帧·s−1) 参数量/106个 Faster R−CNN 91.9 52.7 71.6 137.10 SSD 91.5 55.7 95.1 26.29 RT−DETR 93.3 59.0 88.5 19.87 YOLOv5s 92.7 59.2 109.9 9.11 YOLOv7 93.2 53.5 59.5 36.48 YOLOv8n 92.0 59.0 128.2 3.01 YOLOv8s 93.4 59.9 120.5 11.13 YOLOv8n−MSMLAS 93.4 60.1 80.0 5.80 由表3可看出,YOLOv8n−MSMLAS在mAP@0.5上较Faster R−CNN和SSD分别提升了1.5%和1.9%,在mAP@0.5:0.95上分别提升了7.4%和4.4%。该模型在参数量上表现出显著优势,分别减少了131.3×106和20.49×106个。YOLOv8n−MSMLAS在mAP@0.5和mAP@0.5:0.95上较RT−DETR分别提升了0.1%和1.1%,参数量减少了14.07×106个。YOLOv8n−MSMLAS在mAP@0.5上较YOLOv5s和YOLOv7分别提升了0.7%和0.2%,在mAP@0.5:0.95上分别提升了0.9%和6.6%,参数量分别减少了3.31×106个和30.68×106个。YOLOv8n−MSMLAS在mAP@0.5和mAP@0.5:0.95上较YOLOv8n分别提升了1.4%和1.1%。YOLOv8n−MSMLAS参数量较YOLOv8s减少了5.33×106个。这表明YOLOv8n−MSMLAS在性能与模型复杂度之间达到平衡,能够在提升检测效果的同时有效控制模型大小,降低资源消耗。
为了全面评估模型在矿井复杂场景下的表现,从数据集中挑选具有代表性的样本,包括遮挡目标、光照不均和小尺度目标等典型问题的场景,并利用部分模型分别进行了实验,检测结果如图8所示。
由图8可看出,对于遮挡目标检测任务,YOLOv8n−MSMLAS表现极好,检测出了全部目标,说明该模型在复杂遮挡场景下具备更强目标感知能力,有效提升了模型检测精度,而其他模型均有目标漏检情况,反映出这些模型在处理遮挡问题时的局限性。对于光照不均和多目标稀疏分布场景下的检测任务,虽然所有模型均能较好地检测到目标,但YOLOv8n−MSMLAS在检测结果置信度分数上综合高于其他模型,说明其识别能力更强。在目标尺度差异大的检测任务中,YOLOv8n−MSMLAS借助检测头中引入自适应空间特征融合模块,解决了小目标漏检问题,而其他模型则普遍存在小目标漏检现象。
3. 结论
1) 在YOLOv8n基础上添加MultiSEAM,增强对遮挡目标的检测能力;结合轻量化MLCA机制,削弱光照不均及多目标稀疏分布对检测精度的影响;引入ASFF自适应空间特征融合模块,提升目标尺度差异大的情况下对小尺度目标的检测能力。实验结果显示,与YOLOv8n相比,YOLOv8n−MSMLAS在准确率、mAP@0.5与mAP@0.5:0.95指标上分别提升了5.3%、1.4%和1.1%。
2) 与Faster R−CNN,SSD,RT−DETR,YOLOv5s,YOLOv7等主流模型相比,YOLOv8n−MSMLAS在综合性能上表现最佳,mAP@0.5和mAP@0.5:0.95分别达到93.4%和60.1%,FPS为80.0帧/s,参数量为5.80×106个,较好平衡了模型的检测精度和复杂度。
3) 在煤矿井下复杂场景下,YOLOv8n−MSMLAS在光照不均、目标尺度不一致、遮挡等条件下表现出较好的检测性能,适用于现场检测。
-
表 1 环境配置参数
Table 1 Environmental configuration parameters
环境 配置参数 CPU 12th Gen Intel(R) Core(TM) i7−12650H GPU RTX 3030 (24 GiB)运行环境 Python3.9,CUDA 11.8 深度学习框架 Pytorch 1.12.1 编程语言 Python 3.9.7  下载: 导出CSV
下载: 导出CSV
表 2 消融实验结果
Table 2 Ablation experiment results
模型 MLCA MultiSEAM ASFF 准确率/% 召回率/% mAP@0.5/% mAP@0.5:0.95/% FPS/(帧·s−1) 参数量/106个 YOLOv8n × × × 91.7 87.2 92.0 59.0 128.2 3.01 改进模型1 √ × × 93.7 86.3 92.9 59.1 109.9 3.01 改进模型2 × √ × 96.5 86.2 92.5 58.4 108.7 4.42 改进模型3 × × √ 95.6 88.8 93.4 58.9 104.2 4.38 改进模型4 √ √ × 95.3 89.6 93.4 58.3 101.1 4.43 改进模型5 √ × √ 95.8 85.8 92.9 56.5 91.7 4.38 改进模型6 × √ √ 96.2 89.0 92.6 59.1 88.5 5.80 改进模型7 √ √ √ 97.0 87.3 93.4 60.1 80.0 5.80
下载: 导出CSV
表 3 对比实验结果
Table 3 Comparison experiment results
模型 mAP@0.5/% mAP@0.5:0.95/% FPS/(帧·s−1) 参数量/106个 Faster R−CNN 91.9 52.7 71.6 137.10 SSD 91.5 55.7 95.1 26.29 RT−DETR 93.3 59.0 88.5 19.87 YOLOv5s 92.7 59.2 109.9 9.11 YOLOv7 93.2 53.5 59.5 36.48 YOLOv8n 92.0 59.0 128.2 3.01 YOLOv8s 93.4 59.9 120.5 11.13 YOLOv8n−MSMLAS 93.4 60.1 80.0 5.80
下载: 导出CSV
-
[1] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. IEEE Conference on Computer Vision and Pattern Recognition,New York,2014:580-587.
[2] GIRSHICK R. Fast R-CNN[C]. IEEE International Conference on Computer Vision,Santiago,2015:1440-1448.
[3] REN Shaoqing,HE Kaiming,GIRSHICK R,et al. Faster R-CNN:towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149. DOI: 10.1109/TPAMI.2016.2577031
[4] LIU Wei,ANGUELOV D,ERHAN D,et al. SSD:single shot MultiBox detector[C]. European Conference on Computer Vision,Cham,2016:21-37.
[5] 王渊,郭卫,张传伟,等. 融合注意力机制和先验知识的刮板输送机异常煤块检测[J]. 西安科技大学学报,2023,43(1):192-200. WANG Yuan,GUO Wei,ZHANG Chuanwei,et al. Detection of abnormal coal block in scraper conveyor integrating attention mechanism and prior knowledge[J]. Journal of Xi'an University of Science and Technology,2023,43(1):192-200.
[6] 赵云辉,程小舟,董锴文,等. 基于MK−YOLOV4的矿区人员无标注视频检索方法[J]. 激光与光电子学进展,2022,59(4):301-309. ZHAO Yunhui,CHENG Xiaozhou,DONG Kaiwen,et al. Unlabeled video retrieval method of mining personnel based on MK-YOLOV4[J]. Laser & Optoelectronics Progress,2022,59(4):301-309.
[7] 谢斌红,袁帅,龚大立. 基于RDB−YOLOv4的煤矿井下有遮挡行人检测[J]. 计算机工程与应用,2022,58(5):200-207. DOI: 10.3778/j.issn.1002-8331.2009-0449 XIE Binhong,YUAN Shuai,GONG Dali. Detection of blocked pedestrians based on RDB-YOLOv4 in coal mine[J]. Computer Engineering and Applications,2022,58(5):200-207. DOI: 10.3778/j.issn.1002-8331.2009-0449
[8] 汝洪芳,王珂硕,王国新. 改进YOLOv4网络的煤矿井下行人检测算法[J]. 黑龙江科技大学学报,2022,32(4):557-562. DOI: 10.3969/j.issn.2095-7262.2022.04.023 RU Hongfang,WANG Keshuo,WANG Guoxin. Coal mine pedestrian detection algorithm based on improved YOLOv4 network[J]. Journal of Heilongjiang University of Science and Technology,2022,32(4):557-562. DOI: 10.3969/j.issn.2095-7262.2022.04.023
[9] LI Xiaoyu,WANG Shuai,LIU Bin,et al. Improved YOLOv4 network using infrared images for personnel detection in coal mines[J]. Journal of Electronic Imaging,2022,31. DOI: 10.1117/1.JEI.31.1.013017.
[10] YAO Wei,WANG Aiming,NIE Yifan,et al. Study on the recognition of coal miners' unsafe behavior and status in the hoist cage based on machine vision[J]. Sensors,2023,23(21). DOI: 10.3390/s23218794.
[11] 张磊,李熙尉,燕倩如,等. 基于改进YOLOv5s的综采工作面人员检测算法[J]. 中国安全科学学报,2023,33(7):82-89. ZHANG Lei,LI Xiwei,YAN Qianru,et al. Personnel detection algorithm in fully mechanized coal face based on improved YOLOv5s[J]. China Safety Science Journal,2023,33(7):82-89.
[12] 白培瑞,王瑞,刘庆一,等. DS−YOLOv5:一种实时的安全帽佩戴检测与识别模型[J]. 工程科学学报,2023,45(12):2108-2117. BAI Peirui,WANG Rui,LIU Qingyi,et al. DS-YOLOv5:a real-time detection and recognition model for helmet wearing[J]. Chinese Journal of Engineering,2023,45(12):2108-2117.
[13] 张辉,苏国用,赵东洋. 基于FBEC−YOLOv5s的采掘工作面多目标检测研究[J]. 工矿自动化,2023,49(11):39-45. ZHANG Hui,SU Guoyong,ZHAO Dongyang. Research on multi object detection in mining face based on FBEC-YOLOv5s[J]. Journal of Mine Automation,2023,49(11):39-45.
[14] SHAO Xiaoqiang,LIU Shibo,LI Xin,et al. FM-YOLOv7:an improved detection method for mine personnel helmet[J]. Journal of Electronic Imaging,2023,32(3). DOI: 10.1117/1.JEI.32.3.033013.
[15] 田子建,阳康,吴佳奇,等. 基于LMIENet图像增强的矿井下低光环境目标检测方法[J]. 煤炭科学技术,2024,52(5):222-235. DOI: 10.12438/cst.2023-0675 TIAN Zijian,YANG Kang,WU Jiaqi,et al. LMIENet enhanced object detection method for low light environment in underground mines[J]. Coal Science and Technology,2024,52(5):222-235. DOI: 10.12438/cst.2023-0675
[16] 薛小勇,何新宇,姚超修,等. 基于改进YOLOv8n的采掘工作面小目标检测方法[J]. 工矿自动化,2024,50(8):105-111. XUE Xiaoyong,HE Xinyu,YAO Chaoxiu,et al. Small object detection method for mining face based on improved YOLOv8n[J]. Journal of Mine Automation,2024,50(8):105-111.
[17] 肖振久,严肃,曲海成. 基于多重机制优化YOLOv8的复杂环境下安全帽检测方法[J]. 计算机工程与应用,2024,60(21):172-182. DOI: 10.3778/j.issn.1002-8331.2402-0147 XIAO Zhenjiu,YAN Su,QU Haicheng. Safety helmet detection method in complex environment based on multi-mechanism optimization of YOLOv8[J]. Computer Engineering and Applications,2024,60(21):172-182. DOI: 10.3778/j.issn.1002-8331.2402-0147
[18] FAN Yingbo,MAO Shanjun,LI Mei,et al. CM-YOLOv8:lightweight YOLO for coal mine fully mechanized mining face[J]. Sensors,2024,24(6). DOI: 10.3390/S24061866.
[19] SHAO Xiaoqiang,LIU Shibo,LI Xin,et al. Rep-YOLO:an efficient detection method for mine personnel[J]. Journal of Real-Time Image Processing,2024,21(2). DOI: 10.1007/S11554-023-01407-3.
[20] YU Ziping,HUANG Hongbo,CHEN Weijun,et al. YOLO-FaceV2:a scale and occlusion aware face detector[J]. Pattern Recognition,2024,155. DOI: 10.1016/J.PATCOG.2024.110714.
[21] WAN Dahang,LU Rongsheng,SHEN Siyuan,et al. Mixed local channel attention for object detection[J]. Engineering Applications of Artificial Intelligence,2023,123. DOI: 10.1016/J.ENGAPPAI.2023.106442.
[22] LIU Songtao,HUANG Di,WANG Yunhong. Learning spatial fusion for single-shot object detection[EB/OL]. (2024-08-22]. https://arxiv.org/abs/1911.09516v2.
[23] YANG Wenjuan,ZHANG Xuhui,MA Bing,et al. An open dataset for intelligent recognition and classification of abnormal condition in longwall mining[J]. Scientific Data,2023,10(1). DOI: 10.1038/S41597-023-02322-9.



计量
- 文章访问数: 95
- HTML全文浏览量: 19
- PDF下载量: 28
