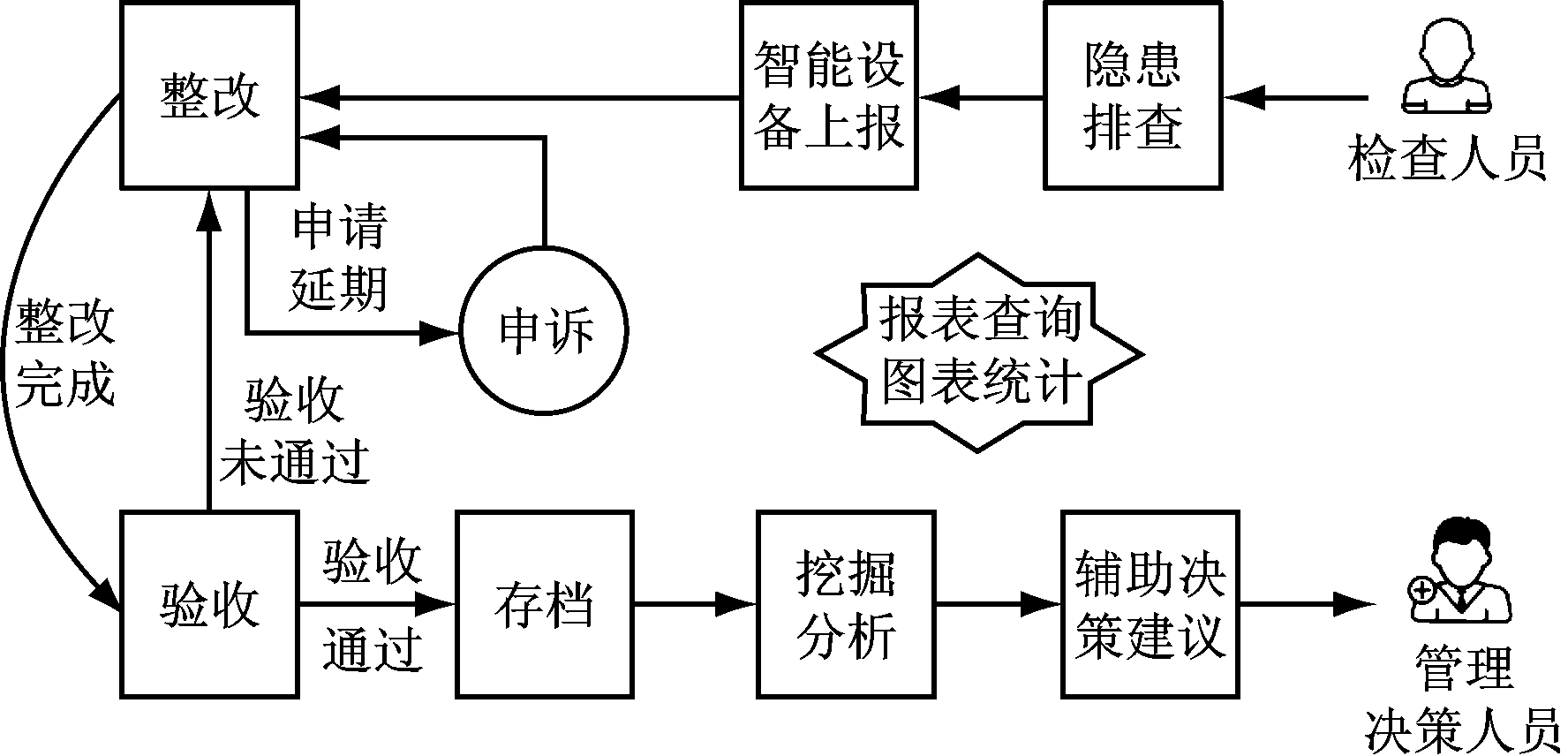
图1 隐患处理流程
陈运启
(中煤科工集团重庆研究院有限公司, 重庆 400039)
摘要:针对目前煤矿隐患管理缺乏对隐患数据深入分析的问题,介绍了适合隐患关联规则发现的数据挖掘算法,提出用支持度-置信度-Kulczynski度量模式表达隐患因素间的关联关系。对隐患数据预处理、转换后构建隐患数据仓库,并在隐患责任部门、隐患种类、隐患等级和隐患发生地点4个维度上进行挖掘分析,发现多维度间存在的较强关联规则,给出针对性的辅助决策。现场实际应用表明,通过使用数据挖掘算法,减少了隐患的发生次数,为煤矿隐患治理提供了可靠支持。
关键词:煤矿隐患; 数据挖掘; 支持度; 置信度; Kulczynski度量; 关联规则
网络出版地址:http://www.cnki.net/kcms/detail/32.1627.TP.20160126.1543.007.html
隐患的排查与整改是煤矿安全生产管理的重要环节,特别是当前安全检查的力度不断加大,暴露出来的各类煤矿安全隐患的数量也越来越多。据统计,2013年中国仅工矿企业排查出的隐患数据就多达500万[1]。为了应对企业隐患的信息化管理要求,各种隐患管理系统的研发与应用也在不断开展。但是,当前多数隐患管理系统基本上只提供对隐患信息的简单记录与查询统计,缺乏对海量隐患数据的深入分析。发现隐患数据中各因素间的关联关系,减少隐患发生次数,提高生产安全指数,是当前煤矿隐患排查治理和信息化发展过程中亟需解决的重要课题之一。本文将数据挖掘算法应用于煤矿隐患管理系统,针对隐患数据在多个维度上展开关联分析与挖掘,为后续隐患管理提供较为准确、可靠的辅助决策。
数据挖掘概念出现于20世纪80年代,是一种多学科综合的产物,其充分利用统计学、数据库、人工智能、模式识别和机器学习等理论与技术,从海量数据中进行自动分析与挖掘,发现潜在的隐含知识,协助用户做出合理决策与准确预测等[2]。目前,数据挖掘相关技术与产品已广泛应用于金融分析、医疗保健、商品销售、行为预测分析等领域。
1.1 数据挖掘过程
对数据挖掘过程的研究有多种,但基本上可归为数据预处理、数据转换、数据挖掘和结果评估与表达4个步骤。
数据预处理是指从数据源中选择要处理的数据对象或数据主题,并对选择的数据进行清理,去掉其中的噪声数据、重复数据,补充不完整或缺失的数据。数据预处理是数据挖掘的重要基础,处理后的数据质量直接决定了整个数据挖掘结果的准确度和可信度。
数据转换是将预处理后的数据根据挖掘需要在数据范围和数据维度上做出一定的计算与选取。往往预处理后的数据在数量级和维度上都比较高,在数据挖掘执行过程中,可能会分批选择不同阶段和不同维度上的数据,并转换为适合数据挖掘算法使用的数据结构。
数据挖掘是在前期处理结果的基础上,利用许多不同方法如决策树方法、神经网络方法、贝叶斯方法、关联分析方法、聚类分析方法等对数据进行挖掘计算,从而发现相应的关联关系和知识模型。
结果评估与表达是数据挖掘过程的最后阶段,其利用适当的可视化技术和知识合理表达数据挖掘的计算结果并呈现给用户,进而评估数据挖掘质量以及知识模型的有效性。
1.2 关联规则算法
所谓关联,就是反映一个事物与其他事物之间的依赖关系。关联规则算法是一种在海量数据中找出这些依赖关系的方法,适用于隐患数据中各因素间关联关系的挖掘与分析。关联规则中的基本概念有项集(Itemset)、支持度(Support)和置信度(Confidence)[3]。
设定存在事务数据库D={t1,t2,…,tn},其中t1,t2,…,tn表示每一个事务;所有项目的集合I={i1,i2,…,im},其中i1,i2,…,im表示每一个项目,每个事务包含的项集都是I的子集。关联规则是支持度和置信度分别满足给定阈值的规则,用形如X⟹Y的蕴涵式来表示(X,Y表示项集),其中支持度表示X⟹Y蕴涵式在事务数据库中出现的频率,即Support(X⟹Y)=P(XUY),置信度表示Y在包含X的事务中出现的频率,即Confidence(X⟹Y)=Support(X⟹Y)/Support(X)=P(Y|X)。
Apriori算法是关联规则挖掘领域中的经典算法,应用非常广泛。Apriori算法的核心是挖掘频繁项集的递推算法,其基本思想是用迭代的方法找出所有的候选集,将这些候选集的支持度与最小支持度比较,如果不小于最小支持度,即为频繁项集。找到频繁项集后,计算规则的置信度,如果所得置信度大于最小置信度,则产生强关联规则[4]。
Apriori算法在搜索频繁项集和挖掘强关联规则时,需要多次扫描事务数据库,同时会产生大量的候选集,算法执行所花费的时间和空间代价都比较大,在挖掘长频繁模式时算法性能较为低下,挖掘的强关联规则也容易产生误导信息。
1.3 支持度-置信度-Kulczynski度量模式
针对Apriori算法存在的缺点,韩家炜提出了FP-Growth(Frequent Pattern Growth,频繁模式增长)算法。FP-Growth算法首先对事务数据库进行分析和处理,生成1-频繁项集,并根据支持度由大到小排序,形成频繁项索引表。然后构建根节点为“null”的FP-Tree(Frequent Pattern Tree,频繁模式树),并对事务数据库中的每个事务进行处理,不断构建FP-Tree分支节点。最后进行FP-Tree挖掘,可采用自底向上的迭代方式,以叶子节点为后缀的项与一起出现的前缀路径组成一个条件模式基[5]。
在生成1-频繁项集时,可以根据支持度大小,限制生成的1-频繁项集的大小,以减少迭代次数,提高挖掘效率。由于FP-Growth算法对事务数据库有效压缩,相比Apriori算法避免了重复扫描事务数据库带来的额外开销;此外,FP-Growth算法还将发现长频繁模式的问题转化为递归模式增长的策略,避免产生大量候选集,大大降低了算法的时间复杂度。
FP-Growth算法采用支持度和置信度表示发现的规则之间的关联性,容易产生误导的关联规则结果,特别是P(X|Y)与P(Y|X)相差较大时,X与Y之间可能具有正相关与负相关2种对立关系。因此增加更有效的Kulczynski度量[6],它仅受条件概率影响,而与事务总数无关,具有零不变性。Kulczynski度量是与X,Y相关的2个关联规则X⟹Y,Y⟹X的置信度的平均值,即Kulczynski(X,Y)=(P(X|Y)+P(Y|X))/2,利用它来扩展支持度-置信度模式,生成支持度-置信度-Kulczynski度量模式,有助于挖掘煤矿隐患多个维度之间更有效的关联规则。
针对隐患数据展开的挖掘分析是在煤矿隐患闭环管理系统基础上展开的。系统基于.NET Framework技术平台实现[7],使用Microsoft SQL Server 2008作为持久层数据库服务器,利用ASP.NET MVC框架[8]并结合Html,CSS,JavaScript,jQuery等前端编程技术与插件实现Web终端报表查询、图表统计、挖掘结果呈现等功能,提供了友好的用户体验。隐患处理流程包含隐患排查、整改、申诉、验收和存档等,系统对存档的数据进行预处理后展开数据挖掘,给出合理的决策建议,如图1所示。
图1 隐患处理流程
2.1 隐患数据预处理与数据转换
为了提高数据挖掘的准确性和速度,在展开挖掘之前对隐患数据进行相应的处理。在综合考虑数据仓库数据更新速度和数据完整性的情况下,设定隐患数据从源数据库中抽取的周期为7 d,抽取过程中去除申诉成功并取消的隐患数据。同时,从隐患自身特点和实际需要出发,决定在隐患责任部门(Department)、隐患种类(Category)、隐患等级(Level)、隐患发生地点(Address)4个维度上进行挖掘分析。隐患种类包括调度类、通风类、采掘类、机运类、地测防治水类、爆炸品与放炮类和共性类;隐患等级依据严重程度由高到低分为A级、B级、C级和D级。在隐患数据载入数据仓库之前,对数据进行精简,只保留隐患的基本信息和以上几个维度信息,可减少冗余数据,提高挖掘效率。
2.2 挖掘分析过程及结果
本文以某煤矿现场的实际隐患数据展开数据挖掘过程并分析隐患各维度间的关联关系,发现较强的关联规则指导现场生产。以该煤矿1个月284条隐患数据为例,经计算后其频繁项索引表前10项见表1。
表1 隐患数据频繁项索引表前10项

从表1可看出,C级、采掘类和B级隐患排名靠前,且掘进二队的隐患数量位居各部门首位,因此以掘进二队为基础,从隐患责任部门、隐患等级和隐患种类3个维度上进行分析,生成相应的FP-Tree如图2所示。
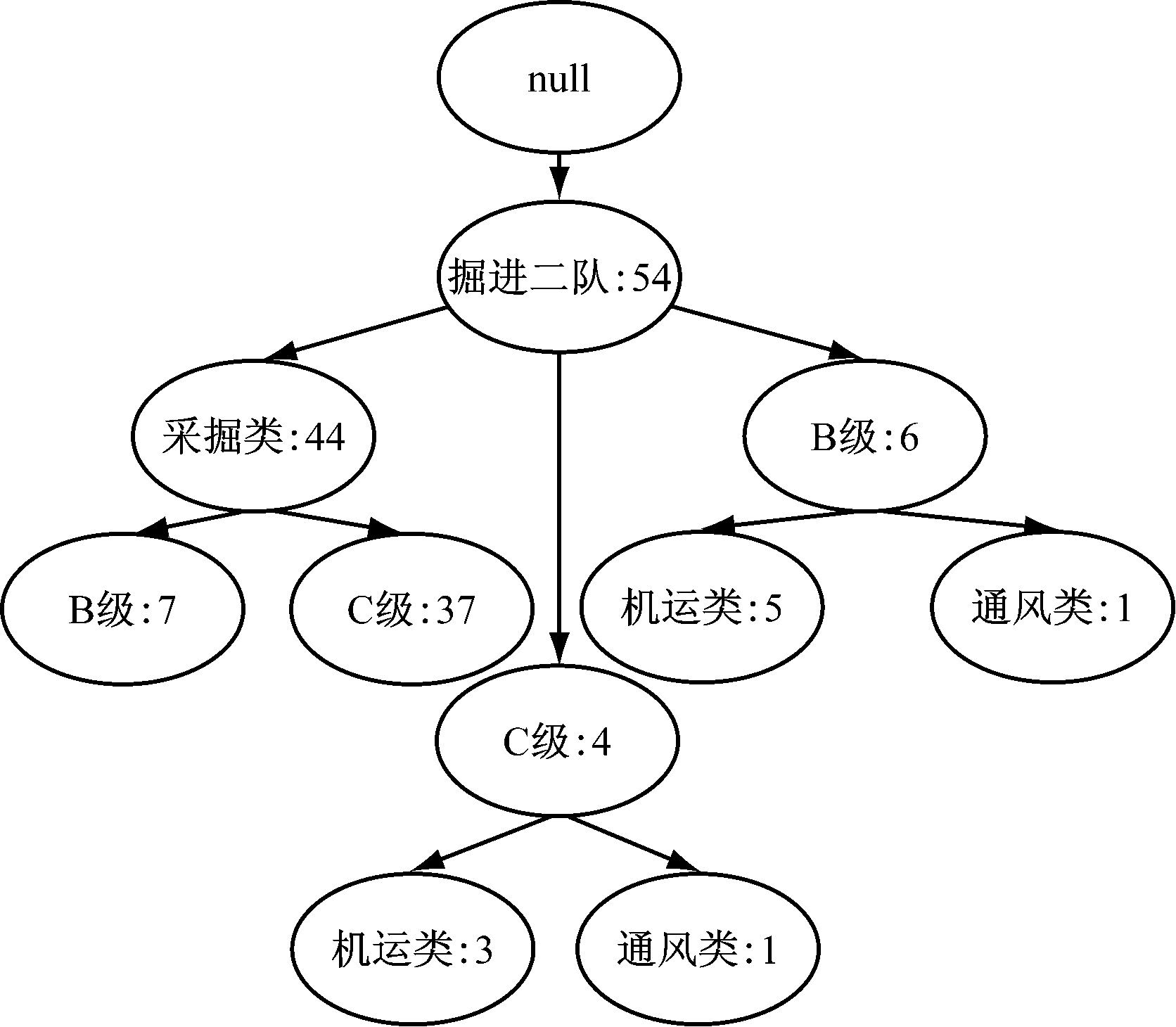
图2 隐患责任部门-隐患等级-隐患种类FP-Tree
从图2可看出,掘进二队负责整改的相关隐患中,采掘类和C级隐患占了非常高的比例,通过计算可得
Department(掘进二队)⟹Category(采掘类)[Support=15.49%,Confidence=81.48%,Kulczynski=52.02%];
Department(掘进二队)Category(采掘类)⟹Level(C级)[Support=13.03%,Confidence=84.09%,Kulczynski=51.40%]。
此外,针对掘进二队的隐患增加隐患发生地点维度的挖掘与分析,其FP-Tree如图3所示,其中4321-38运输巷隐患总数为29条,+1 600 m进风斜井隐患总数为18条。通过计算可得
Department(掘进二队)⟹Address(4321-38运输巷)[Support=10.21%,Confidence=53.70%,Kulczynski=75.18%];
Department(掘进二队)⟹Address(+1 600 m进风斜井)[Support=6.69%,Confidence=33.33%,Kulczynski=64.03%]。

图3 隐患责任部门-隐患发生地点FP-Tree
2.3 辅助决策
从掘进二队在陷患种类和隐患等级维度上的挖掘结果可看出,掘进二队与采掘类和C级隐患的关联关系更强。因此,建议掘进二队在处理隐患时,将重点放在采掘类和C级隐患上。
对掘进二队隐患发生地点维度上的数据进行挖掘分析后可看出,掘进二队的主要隐患发生地点集中在4321-38运输巷和+1 600 m进风斜井处,且相比置信度而言,Kulczynski度量值更高,表明该2个地点发生的隐患与掘进二队的关联性更强。因此建议掘进二队着重处理该2个地点的隐患。
通过以上计算和分析,就掘进二队而言,在隐患发生地点、隐患种类和隐患等级上,均给出了有数据支持的辅助决策。在随后1个月的隐患治理整改中,掘进二队负责整改的隐患占全矿隐患的比例由19.01%下降至13.50%,效果非常明显。
数据挖掘技术在煤矿隐患管理中的应用,给隐患治理提供了切实可用的决策建议,使隐患得到了针对性整治,隐患发生率有较大幅度降低,生产安全状况得到明显改善。产生煤矿安全隐患的关联因素较多,其中煤矿人员的专业素质、培训考试信息、年龄结构层次等数据也是潜在的重要关联点,所以在下一步的研究中,计划将以上数据抽取、转换后装载到数据仓库中,建立包含“人”的因素在内的挖掘分析模型,进行更深层次、更广维度的关联分析挖掘,发现“人”的因素对煤矿隐患产生的影响情况,提供更为全面的辅助决策。
参考文献:
[1] 张大伟.基于OLAM的煤矿企业安全隐患趋势分析[J].煤炭工程,2015,47(5):139-142.
[2] 王梦雪.数据挖掘综述[J].软件导刊,2013,12(10):135-137.
[3] 芦海燕.数据挖掘中关联规则算法的研究[J].电脑知识与技术,2011,7(26):6324-6325.
[4] 黄伟力,李亮.基于Apriori的煤矿安全预警系统设计[J].计算机测量与控制,2013,21(10):2786-2788.
[5] 章志刚,吉根林.一种基于FP-Growth的频繁项目集并行挖掘算法[J].计算机工程与应用,2014,50(2):103-106.
[6] 曲广龙,杨洪耕.基于梯形云模型的电能质量数据关联性挖掘方法[J].电力系统自动化,2015,39(7):145-150.
[7] 李璟.基于.NET的分层架构及抽象工厂模式在Web开发中的应用[J].软件导刊,2015,14(4):105-108.
[8] 秦冠男.基于ASP.NET MVC框架的IT管理系统的设计[D].上海:上海交通大学,2013.
CHEN Yunqi
(CCTEG Chongqing Research Institute, Chongqing 400039, China)
Abstract:For lack of deep analysis of hidden hazard data in current coal mine hidden hazard management, data mining algorithms which were suitable for discovering association rule of hidden hazard were introduced, and support-confidence-Kulczynski model was proposed to indicate association relationship among hidden hazard factors. Data warehouse is built after preprocessing and conversion of hidden hazard data, and mining analysis is conducted on four dimensions such as department, category, level and address of hidden hazard, so as to provide corresponding assistant decision-making according to strong association rule founded among dimensions. The actual application results show that occurrence of hidden hazard is reduced and reliable support is provided for coal mine hidden hazard management by use of the data mining algorithm.
Key words:coal mine hidden hazard; data mining; support; confidence; Kulczynski measurement; association rule
作者简介:陈运启(1984-),男,安徽萧县人,助理研究员,硕士,主要从事煤矿综合自动化与信息化等方面的研究工作,E-mail:chen.yun.qi@qq.com。
基金项目:工信部2014年物联网发展专项资金项目(2014083105)。
收稿日期:2015-11-13;修回日期:2016-01-10;责任编辑:盛男。
中图分类号:TD67
文献标志码:A 网络出版时间:2016-01-26 15:43
文章编号:1671-251X(2016)02-0027-04
DOI:10.13272/j.issn.1671-251x.2016.02.007
陈运启.数据挖掘技术在煤矿隐患管理中的应用[J].工矿自动化,2016,42(2):27-30.